이번 포스팅에서는 Arkabandu Chowdhury가 ICCV 2021에서 발표한 "Few-Shot Image Classification: Just Use a Library of Pre-trained Feature Extractors and a Simple Classifier"을 읽고 정리해 보도록 하겠습니다.
1. Introduction
Few-shot classification의 few-shot learner는 먼저 학습 데이터셋에 대해 학습을 시키고, 적은 양(few)의 데이터만으로 few distribution의 데이터에 대해 잘 일반화하는 것이 학습 목적입니다. 이때, 어떤 few distribution을 사용해야 할 지 모르므로, 본 논문에서는 최대한 다양한 feature를 가진 데이터셋에서 학습된 모델이 유리할 것이라고 가정했습니다.
이러한 데이터셋의 예시는 ImageNet의 subset인 ILSVRC2012(1.3M images, 1K classes)나 full ImageNet(over 20K classes)가 있습니다. 이 중에서 ILSVRC2012로 학습된 모델들은 모델 설계자로부터 아주 정교하게 학습되었습니다. 본 논문에서는 이러한 모델들을 library-based learner라고 불렀습니다.
만약 이런 library-based learner가 few-shot classification에서 성능이 우수하다면, 이런 모델들을 함께 사용하는 방법도 좋은 성능을 기대할 수 있을 것 입니다. 본 논문에서는 library-based learner를 함께 사용하여 full learner를 구성했습니다.
2. High Accuracy of Library-Bases Learners
2.1 Designing a Library-Based Learner
Library-based learner를 few-shot classification task에 사용하기 위해 본 논문에서는 기존 모델의 classifier를 제거하고 하나의 hidden layer를 가진 MLP(Multi-Layered Perceptron)을 붙이고 L2 regularization으로 학습시켰습니다. 그리고 기존 모델의 feature extractor는 freeze하여 더이상 weight가 업데이트 되지 않도록 하였습니다.
2.2 Evaluation
본 논문에서는 library-based learner로 ResNet18, ResNet34, ResNet50, ResNet101, ResNet152와 DenseNet121, DenseNet161, DenseNet169, DenseNet201로 총 9개의 모델을 사용했습니다. 이러한 모델은 모두 ILSVRC2012에서 pre-train되었습니다.
본 논문에서는 hyperparameter search를 위해 CUB 데이터셋을 사용했으며, 테스트 데이터셋으로 FGVC-Aircraft, FC100, Ominglot, Traffic Sign, FGCVx Fungi, Quick Draw, VGG Flower를 사용했습니다.
그리고 few-shot N-way K-shot task에서 N은 {5,20,40} 중에서, K는 {1,5} 중에서 선택하여 사용했습니다. 각각의 library-based learner를 각각의 dataset에 5way1shot, 20way1shot, 40way1shot task에서 실험한 결과는 아래와 같습니다.

그리고 이를 기존의 state-of-the art 방법들과 비교한 결과는 아래와 같습니다. 아래는 5-way, 5-shot task입니다.

Ominglot 데이터셋을 제외하곤 모든 best library-based learner가 기존의 방법보다 좋은 성능을 보이는 것을 확인할 수 있습니다. 그 다음으로 아래는 20-way, 5-shot task에서의 실험결과입니다.

20-way, 5-shot task로 오니 기존 방법과의 격차가 더욱 심해졌고 심지어는 worst library-based learner도 Ominglot을 제외한 기존의 방법보다 좋은 성능이 나오는 것을 확인할 수 있습니다.
3. A Simple Full Library Classifier
3.1 Extreme Variation in Few-Shot Quality
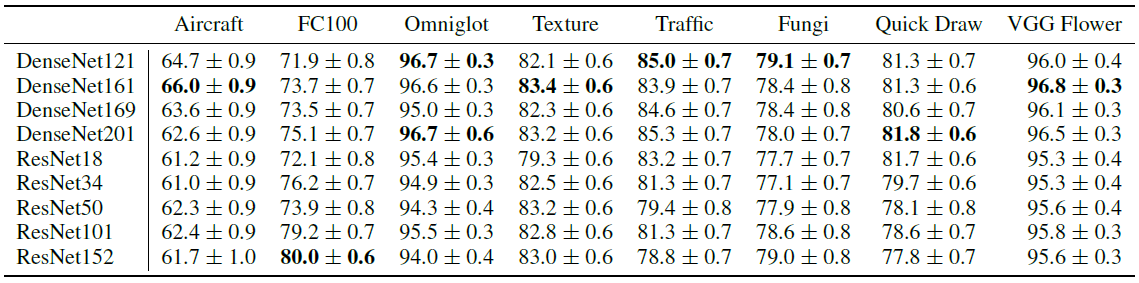
위 표는 5-way, 5-shot task에서 각각의 library-based learner가 각각의 데이터셋에 대해 보이는 성능을 나타낸 것입니다. 어떤 모델이 대체로 우수하다 라는 일관성은 나타나지 않았습니다.
3.2 Combining Library-Based Learners
그래서 본 논문에서는 위 9개의 모델을 함께 사용하고자 했습니다. 여러가지 모델을 함께 사용하고자 했을 때 떠올릴수 있는 방법은 ensemble입니다. 본 논문에서는 hard와 soft 둘 로 ensembled network를 구성했습니다. 또 떠올릴 수 있는 다른 방법은 9개의 feature extractor에서 나온 output을 모두 합쳐 하나의 classifier에 입력우로 주는 것 입니다. 본 논문에서는 이를 full library learner라고 명명했고, full library learner의 classifier는 13984개의 feature를 입력으로 받습니다.

그리고 hard ensemble, soft ensemble, full library와 single library-based learner를 여러 task에서 비교했습니다. 실험 결과는 다음과 같습니다.

어떤 single library-based learner도 여러 learner를 사용한 것 보다 성능이 우수하게 나오지 않았습니다.
4. Data vs. Diversity: Who Wins?
이번에는 보다 더 큰 데이터셋에서 pre-train된 하나의 모델(data)이 우수할지 아니면 상대적으로 작은 데이터셋에서 pre-train된 여러 모델(diversity)이 우수할지 실험을 진행했습니다. 상대적으로 큰 데이터셋은 full ImageNet을 사용했는데, 해당 데이터셋에서 pre-train된 모델로 구글의 Big-Transfer(BiT) 종류의 모델을 사용했습니다. 사용된 모델은 BiT-ResNet-101-3, BiT-ResNet-152-4, BiT-ResNet-50-1을 사용했고 세 모델 모두 각 논문 저자의 pre-train된 모델을 그대로 가져다 썼습니다. 이 세 모델과 본 논문의 full library learner를 여러 task에서 비교한 결과는 아래와 같습니다.
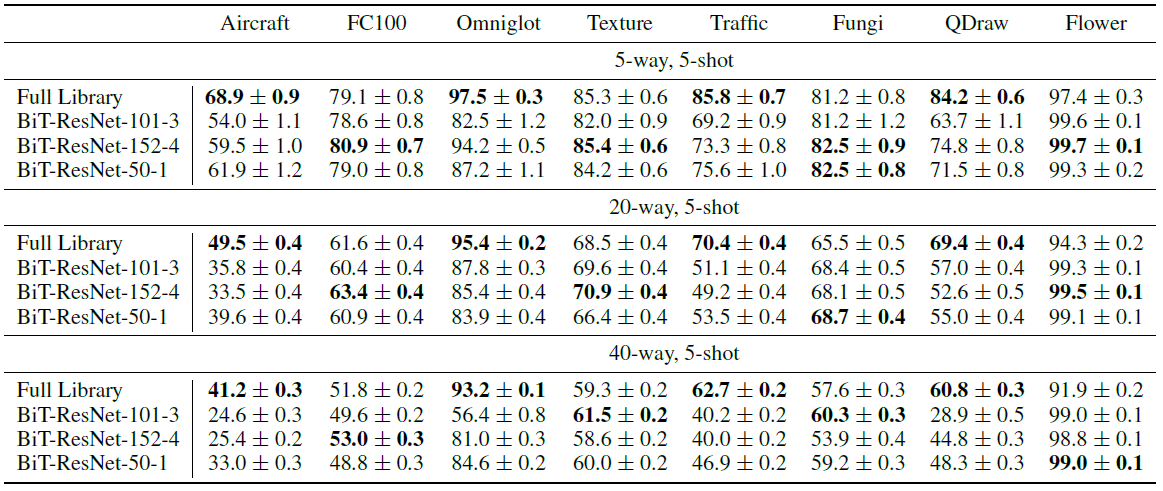
5-way, 5-shot task에서는 비슷한 결과가 나왔으나 way의 수가 증가할 수록 본 논문의 방법과 BiT 종류의 모델의 격차가 벌어지는 것을 알 수 있었습니다.
5. Why Does This Work?
5.1 Few-Shot Fine-Tuning Is Surprisingly Easy
본 논문에서는 왜 여러 pre-trained feature extractor를 사용하는 것이 기존의 방법보다 효과적으로 나타는 지 알아보고자 하였습니다. 그래서 본 40-way, 1-shot task와 40-way이지만 전체 데이터를 사용하는 task에서 weight들의 correspondence를 측정하고자 했습니다.
이때, 학습에는 single-layered perceptron을 classifier로 사용하는 full library를 regularization없이 사용했습니다. 그 다음에 각 모델의 output에 L1 norm을 적용시키고 Pearson Correlation을 계산한 결과, 아래와 같은 결과가 얻어졌습니다.

Traffic signs 데이터셋을 제외하곤 correlation이 높게 나오는 것으로 보아 두 task에서 shot의 개수는 큰 차이가 없었고, 그렇기 때문에 본 full library가 효과적이라고 합니다.
5.2 Different Problems Utilize Different Features
이번에는 데이터셋 간의 유사도를 측정했습니다. 이전과 유사하게 single-layered perceptron을 classifier로 사용하는 full library를 regularization 없이 40-way, full-shot task에서 학습시켰습니다. 그리고, 모델의 output으로 부터 L1 norm이 상위 20%인 것 들만 사용했는데, 중요한 feature들만 고르기 위해서 입니다. 그리고 데이터셋간의 Jaccard Similarity를 측정하는데 완전히 무작위로 추출하면 0.111을 얻을 수 있을것입니다. 결과는 아래와 같습니다.
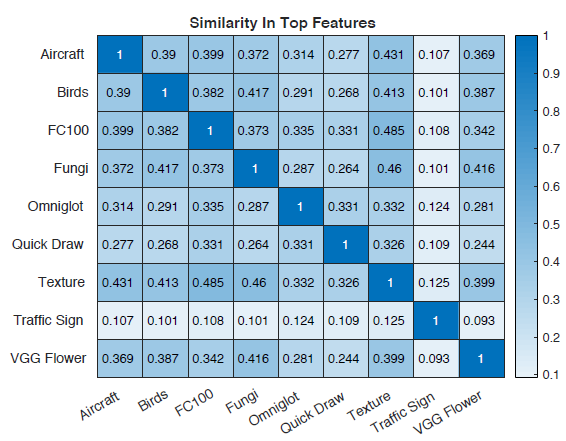
그 결과 데이터셋 간의 similarity가 다 작게나오는 것으로 보아, 각각의 데이터셋들이 상이하고 그로인해 여러 feature extractor로부터 feature를 다양하게 추출하는 것이 효과적이라고 합니다.
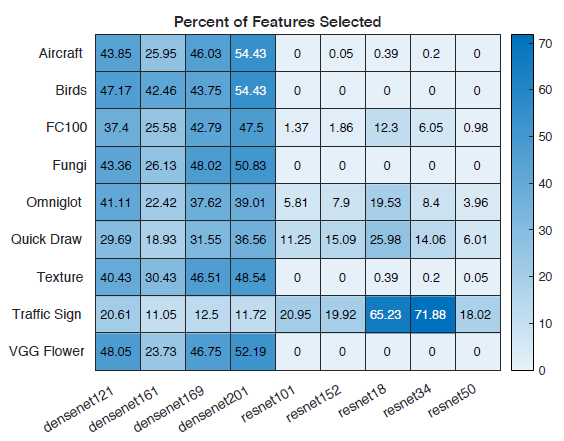
위 그림은 실제로 각각의 모델에서 상위 20% L1 norm으로 선택된 feature들을 표시한 것인데, 각각의 모델마다 같은 데이터셋일지라도 다른 비율로 선택된 것을 확인할 수 있습니다.
6. Conclusion
본 논문에서는 여러 deep CNN 모델을 고품질의 few-shot learner의 토대로 삼는 시험을 진행했습니다. 그 결과, 하나의 deep CNN일지라도 뛰어난 성능을 보였고, 여러 CNN을 사용했을 때는 성능이 더 우수하게 나왔습니다.




댓글