이번 포스팅에서는 Bingchen Liu가 ICLR 2021 에서 발표한 "Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis"를 읽고 정리해 보도록 하겠습니다.
1. Introduction
대부분의 SotA GAN은 연산량이 많고, 많은 학습 데이터를 필요로 하기 때문에 데이터의 수가 적고 컴퓨팅 자원이 한정되어있는 경우에서는 적용시키기 어렵습니다. 희귀병에 대한 의료 이미지나, 특정 연예인의 사진, 특정한 화가의 그림 등의 경우와 같이 데이터의 수가 한정되어 있는 경우에는 주로 pre-trained model을 transfer learning하여 해결하려고 시도합니다. 그러나 pre-training dataset들이 이러한 few-shot dataset에 호환된다는 보장은 없기에 무작정 적용하기도 힘듭니다. 게다가 예술작품을 생성하는 문제에서 pre-trained model을 사용하게 되면 아무래도 pre-training dataset에 biased 될 수 있기 때문에 그다지 선호하지 않을 수도 있습니다.
Few-shot image generation을 하려는 많은 시도는 있었지만 모두 1024x1024 정도의 고해상도의 이미지를 다룰 때 computational cost가 매우 높았습니다. 본 논문에서는 낮은 computational cost와 적은 training image를 가지고 고해상도의 이미지를 생성하는 unconditional GAN을 학습시키고자 합니다. 그러기 위해 빠르게 학습하는 generator와 generator에게 지속적으로 유용한 signal을 주는 discriminator가 필요하게 됩니다.
2. Related Work
Depth-wise convolution을 적용하거나, GAN의 목적함수를 최적화하거나, core-set selection을 통해 각각의 batch를 준비하는 등 GAN을 빠르게 학습시키기 위한 많은 방법들이 연구되어왔습니다. 그러나 이런 방법으로 인한 학습 속도의 향상은 한계가 존재했습니다. 그리고 이로 인해 생성된 이미지는 품질이 그닥 좋진 않았습니다.
고해상도 GAN의 학습 또한 많은 어려움이 있습니다. 첫 번째로, 증가한 모델의 parameter들은 융통성없는 gradient로 이어져 generator를 학습시키기 어렵습니다. 두 번째로, 이미지의 크기가 1024x1024인 target distribution은 매우 sparse 합니다. 다른 연구에서 multi-scale GAN을 통해 고해상도의 GAN을 학습시키려 해 보았지만, 이런 경우 computional cost가 큽니다.
Mode-collapse는 GAN을 학습시키는데 매우 큰 문제입니다. 이는 학습 데이터가 적어지면 더욱 크게 발생하는데 discriminator가 주어진 적은 데이터셋에 오버피팅되어 generator를 학습시키기 위한 의미있는 signal을 줄 수 없게 되기 때문입니다. 다른 연구에서는 다른 목적함수를 고안하거나, 모델의 가중치를 normalize하거나, 학습 데이터에 augmentation을 적응하는 등 discriminator를 규제하려고 노력하였지만 batch-size가 제한된 경우에는 효과를 보기 어려워집니다. 반면에 discriminator에 self-supervised learning을 적용시키면 효과적이라는 연구 결과도 있었습니다. 그러나 그런 연구 또한 computational cost가 제한되어있는 환경에서는 적용시키기 힘들어지고 저해상도 이미지에 국한되어 있었습니다.
3. Method
본 논문에서는 generator의 각각의 해상도마다 하나의 conv layer를 사용합니다. 그리고 512x512 이상의 고해상도에 대해서는 conv layer에서 하나의 channel만 사용합니다.
3.1. Skip-layer channel-wise excitation
고해상도의 이미지를 합성하기 위해 generator는 불가피하게 깊어질 수 밖에 없습니다. 그러나 깊어진 모델은 학습 시간이 더 오래 소요될거고 gradient가 제대로 전달되지 않을 수도 있습니다. 깊은 모델을 학습시키기 위해 ResNet 논문에서는 Residual Block (ResBlock)을 사용하는데, layer간에 skip-connection을 두어 gradient signal을 강화하는 역할을 합니다. 그러나 ResBlock을 사용한 다른 GAN 아키텍쳐에서는 연산량의 증가로 이어졌습니다.
본 논문에서는 skip-connection에 두 가지 아이디어를 덧붙여 Skip-Layer Excitation (SLE)을 고안했습니다. 첫 번째로, 기존의 ResBlock은 서로 다른 conv layer의 channel 간의 addition으로 구현되어 두 conv layer의 channel이 동일해야 했지만, SLE는 channel-wise multiplication을 적용하여 연산량을 크게 줄였습니다. 두 번째로, 기존의 GAN 모델들은 skip-connection은 같은 해상도 끼리만 이루어졌습니다. 그러나 SLE는 같은 spatial-dimension이 더이상 필요하지 않기 때문에 다양한 해상도 범위 (8x8과 128x128, 16x16과 256x256, 32x32와 256x256)에서 이루어지게 하였습니다. 수식으로 표현하면 아래와 같습니다.
\[y=\mathcal{F}(x_{low},\{W_i\}){\cdot}x_{high}\]
여기서 \(x,y\)는 각각 SLE 모듈에서 입력과 출력의 feature map입니다. 함수 \(\mathcal{F}\)는 \(x_{low}\)에 대한 연산들이 포함하고있고 \(W_i\)는 학습 될 모듈의 가중치입니다.
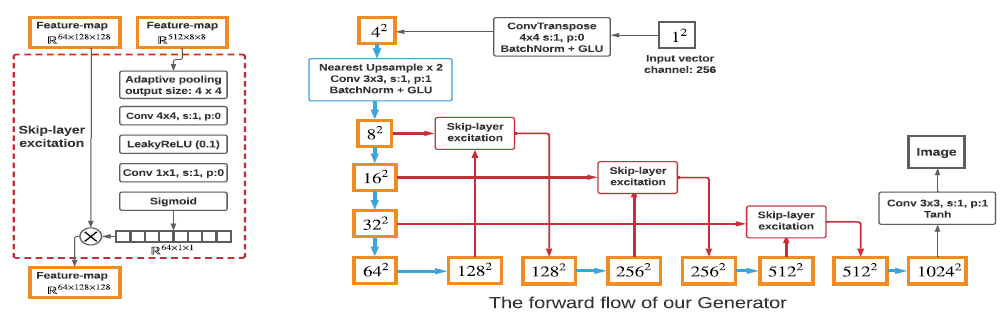
위 그림의 왼쪽은 실제 SLE 모듈을 나타낸 것입니다. \(x_{low}\)와 \(x_{high}\)는 각각 8x8, 128x128의 해상도를 갖고있습니다. 첫번째로 adaptive average-pooling layer가 \(x_{low}\)를 spatial-dimension 따라 4x4로 down-sample 합니다. 그 다음에 conv-layer가 1x1로 down-sample 합니다. LeakyReLU를 거쳐 또 다른 conv-layer가 \(x_{high}\)와 같은 채널수로 맞춰주고 sigmoid를 거칩니다. 그 다음 \(x_{high}\)에 channel dimension에 맞춰 곱해집니다.
SLE는 부분적으로 Squeeze-and-Excitation (SE) 모듈 (Hu et al.)과 닮아있습니다. 그러나 SE는 하나의 feature-map에서 self-gating module의 역할을 수행합니다. 이에 반해 SLE는 서로 동떨어진 feature-map 사이에서 동작합니다. SLE는 SE처럼 channel-wise feature re-calibration을 수행하지만, 동시에 ResBlock처럼 gradient를 강화하는 역할도 수행합니다. SLE의 channel-wise multiplication은 style-transfer에 널리 적용된 Instance Normalization과도 유사합니다. SLE는 StyleGAN처럼 generator가 style과 content를 자동으로 분리할 수 있게 합니다.
3.2. Self-supervised discriminator
본 논문에서는 discriminator를 하나의 encoder로 보고 이를 여러개의 작은 decoder로 학습시킵니다. 이러한 auto-encoding 학습은 discriminator로 하여금 decoder가 좋은 reconstruction하기 좋은 image feature를 추출하도록 하게합니다. Decoder들은 discriminator와 함께 최적화되고 실제 이미지로만 학습됩니다. 수식은 아래와 같습니다.
\[\mathcal{L}_{recons}=\mathbb{E}_{f\sim{D_{encode}}(x),x\sim{I_{real}}}[\parallel\mathcal{G}(f)-\mathcal{T}(x)\parallel]\]
여기서 \(f\)는 discriminator의 중간 feature-map이고, \(\mathcal{G}\)는 \(f\)와 decoder에 대한 처리를 포함하고 있으며 \(\mathcal{T}\)는 실제 이미지 \(I_{real}\)로부터 샘플링된 \(x\)에 대한 처리를 나타냅니다. 전체적인 discriminator는 아래와 그림에 나타나 있습니다.
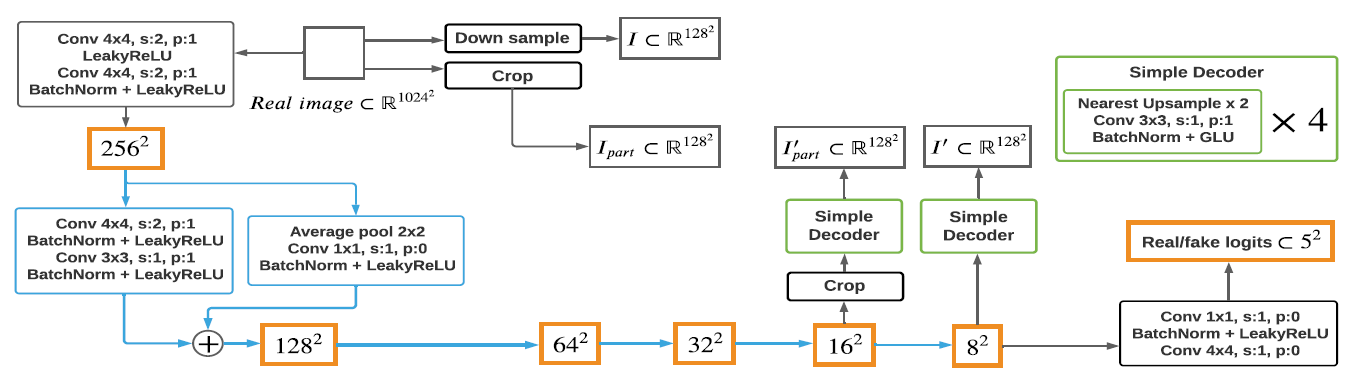
본 논문에서는 두 해상도의 feature-map에서 다른 decoder를 사용했습니다. \(f_1\)은 16x16, \(f_2\)는 8x8 해상도에 해당합니다. 각 decoder는 4개의 conv layer를 갖고 있으며 128x128 해상도의 이미지를 생성합니다. 본 논문에서는 \(f_1\)에서 \(1/8\) 크기로 무작위로 crop합니다. 그리고 같은 양 만큼 실제 이미지에서 crop하여 \(I_{part}\)를 얻어냅니다. 실제 이미지를 resize하여 \(I\)를 얻어냅니다. Decoder들은 cropped \(f_1\)에서 \(I'_{part}\)를 얻어내고 \(f_2\)에서 \(I'\)를 얻어냅니다. 그 다음에 최종적으로 discriminator와 decoder들은 이전에 사용되었던 수식을 이용해 loss를 줄입니다.
이러한 reconstructive training은 전체적인 구성 (\(f_2\)) 뿐만 아니라 상세한 feature(\(f_1\))에 대한 표현까지 추출합니다. 본 논문에서 적용한 auto-encoding 방식은 전형적인 self-supervised learning의 한 방법입니다. 이런 방법은 모델의 robustness와 generalization ability를 향상시킨다고 알려져있습니다.
정리해서, 본 논문에서는 hinge adversarial loss를 사용해서 반복적으로 discriminator와 generator를 학습시켰습니다. 다른 loss function는 성능의 차이가 좀 있었지만, hinge loss가 가장 빠르게 연산되었습니다.
\[\mathcal{L}_D=-\mathbb{E}_{x\sim{I_{real}}}[\min(0,-1+D(x))]-\mathbb{E}_{\hat{x}\sim{G(z)}}[\min(0,-1-D(\hat{x}))]+\mathcal{L}_{recons}\]
\[\mathcal{L}_G=-\mathbb{E}_{z\sim{\mathcal{N}}}[D(G(z))]\]
4. Experiment
사용된 데이터셋은 다음과 같습니다.
- Resolution of 256x256
- Animal-Face Dog and Cat
- 100-shot-Obama
- Panda
- Grumpy-cat
- Resolution of 1024x1024
- Flickr-Face-HQ
- Oxford-flowers
- art paintings from WikiArt
- photographs on natural landscape
- Pokemon
- anime face
- skull
- shell
Metric은 합성된 이미지의 의미적인 현실감을 측정하기 위해 FID를 사용했습니다. 데이터의 수가 1000개 미만인 경우, generator는 5000개의 이미지를 생성하고, 생성된 이미지와 전체 학습 데이터와의 FID를 측정했습니다. LPIPS는 두 이미지간의 perceptual distance를 나타내는데 본 논문에서는 실제 이미지가 주어졌을때 generator에 latent space back-tracking을 수행할 때 reconstruction quality를 측정할 때와 auto-encoding의 성능을 측정할 때 사용되었습니다.
비교군은 StyleGAN2과 본 논문의 방법이 ablate된 baseline을 사용했습니다. 최근의 StyleGAN2는 few-shot setting을 위해 model configuration과 differentiable data-augmentation이 적용됐는데, 실험에선 해당 사항이 적용된 StyleGAN2를 사용했습니다. StyleGAN2는 computational cost가 매우 크기 때문에 본 논문에서는 새로운 baseline을 설계하여 사용했습니다. Baseline은 spectral-normalization, exponential-moving-average optimization on generator, differentiable-augmentation, GLU in genetator를 적용한 DCGAN을 사용했습니다. 그리고 SLE와 self-supervised discriminator를 적용하여 본 논문의 모델을 만들었습니다.

위 표는 여러 network의 computational cost를 나타낸 것입니다. 0.25 StyleGAN2의 경우 1024x1024에서 수렴하지 못하여 이후의 다른 실험에서는 0.5 StyleGAN2를 사용했습니다.
4.1. Image synthesis performance
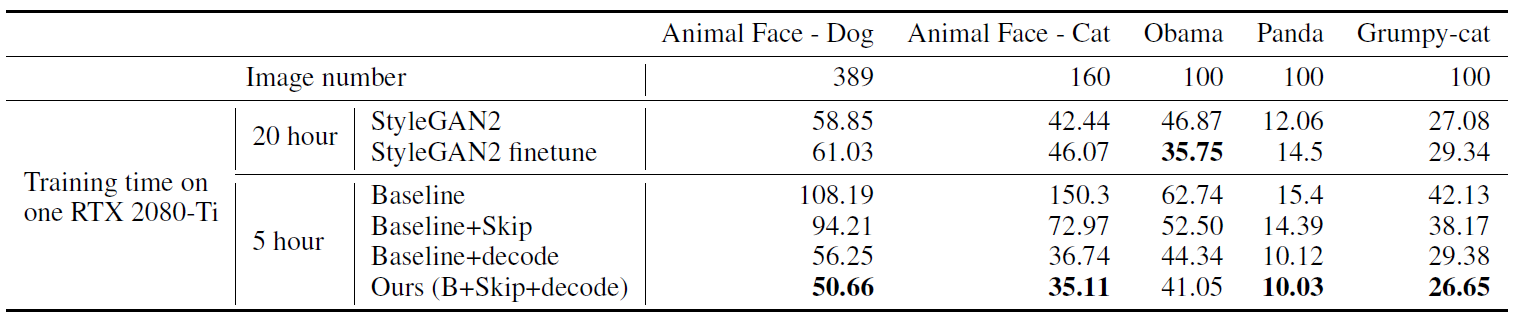

여러 dataset에 걸쳐 FID를 측정한 결과 본 논문의 방법이 좋은 품질의 이미지를 생성할 뿐만 아니라 더 효율적인 연산을 하는 것을 알 수 있습니다.
Pre-trained GAN을 fine-tuning하는 것은 few-shot image generation 분야에서 자주 사용되는 방법입니다. 그러나 이 방법은 source domain과 target domain 사이의 유사성에 달려있는데, 만약 두 도메인이 유사하지 않는다면 오히려 성능이 떨어질 수도 있습니다. 위 두 표의 StyleGAN2 finetune은 FFHQ로 학습된 StyleGAN2를 Freeze-D를 사용해 fine tuning 한 것입니다. 그 결과, FFHQ와 비슷한 Obama나 Anime Face의 경우 좋은 성능이 나왔습니다.
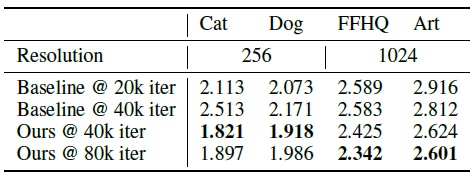
그리고 256x256에서 ablation study도 함께 진행했습니다. Baseline에 비해 SLE(skip)를 적용한 것 보다 decoding-on-D (decode)를 적용한 것이 더 큰 효과를 갖는것으로 나타났고, StyleGAN2와 baseline은 표에 나타난 학습 시간 이후로 빠르게 발산한데 비해 본 논문의 방법은 총 20시간 이후까지도 좋은 품질의 이미지를 생성하였는데 이는 discriminator에 대한 regularization의 효과입니다.

이번에는 1024x1024 해상도에서 더 충분한 데이터를 가지고 실험해보았는데 이때는 온전한 StyleGAN2를 Art와 Photograph에서는 batch size 16과 두개의 TITAN RTX로 5일 가량 학습시켰고 FFHQ에 대해서는 Zhao et al.의 pretrained model을 사용했습니다. 그러나 본 논문의 모델은 batch size 8으로 하나의 2080-Ti로 24시간 밖에 걸리지 않았습니다. 본 논문의 모델을 7만장의 FFHQ에서는 32의 batch size를 사용했습니다. 그 결과 StyleGAN2의 성능이 매우 우수하게 나왔지만 연산량과 데이터의 크기 측면에서 본 논문의 방법도 충분히 견줄만 하다고 합니다.

위 사진은 qualitative result입니다. StyleGAN2의 경우 학습시간이 오래 걸리면서도 mode collapse가 발생한 것을 알 수 있습니다. 그러나 본 논문의 방법은 만족스러운 이미지를 지속적으로 생성하고 있습니다. 주목할만한 점은 Flower, Shell. Pokemon을 학습시키는데는 단 3시간밖에 걸리지 않았다는 것입니다.
4.2. More analysis andn applications
잘 학습된 GAN이면 실제 이미지를 generator의 latent space로 되돌려 latent vector를 조절하며 이미지의 내용을 변경할 수 있습니다. 본 논문에서는 데이터셋의 학습: 테스트 비율을 9:1로 나누어 학습시키고 테스트 데이터와 back-tracked vector에 대해 reconstruction loss를 측정했습니다.
그리고 두 실제 이미지의 back-tracked vector의 interpolation을 통해 생성된 이미지는 아래와 같습니다.

실험 결과 본 논문의 방법이 mode collapse 현상이 거의 나타나지 않는 것을 확인할 수 있습니다.
이번에는 다른 self-supervision 방법들에서 discriminator를 학습시켰을 때의 차이를 확인해보았습니다. 모든 실험은 1만장의 데이터와 batch size 8로 진행되었습니다.
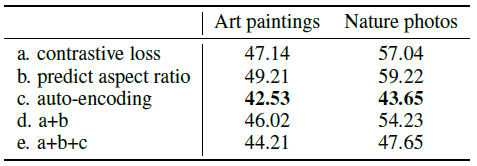
그 결과 다른 두 방법(a,b) 각각과 둘을 합친것, 본 논문의 방법과 함께 사용한것(a,b,c)보다 본 논문에서 사용된 auto-encoding이 가장 좋은 성능을 냈습니다.
마지막으로 StyleGAN2 처럼 content와 style을 분리하는 실험을 진행했습니다.

본 논문의 방법은 1024x1024의 고해상도 상황에서도 성공적으로 style과 content를 분리할 수 있었습니다.
5. Conclusion
본 논문에서는 100장 이하의 고해상도 이미지와 제한된 연산 자원 속에서도 고품질의 합성을 하는 GAN을 학습시켰습니다. 13개의 데이터셋에 걸쳐 진행 실험에서 본 논문의 SLE와 self-supervised regularization on discriminator가 효과적이었음을 보였습니다.



댓글