이번 포스팅에서는 Zheng Gu가 ICCV 2021에서 발표한 "LoFGAN: Fusing Local Representations for Few-shot Image Generation"을 읽고 정리해 보도록 하겠습니다.
1. Introduction
Few-shot image generation 문제에서의 목표는 적은 수의 novel category의 이미지가 주어졌을 때 해당 category에 대한 다양한 이미지를 생성해 내는 것입니다. 이때, 일반적으로 GAN들은 충분한 labeled category와 이미지가 있는 보조 데이터셋을 사용하여 학습시킵니다. 그다음 학습에 사용되지 않은 unseen category의 이미지 몇 장을 주어주고 다양한 이미지를 생성하도록 합니다. Few-shot image generation의 접근 방법으로는 크게 세 가지가 있습니다.
Transformation-based 방법은 하나의 conditional image 에 대해 intra-category transformation을 적용합니다. Optimization-based 방법은 meta-learning을 적용하여 unconditional image generation task에서 initialization strategy를 학습합니다. 그리고 Fusion-based 방법은 metric-based few-shot learning에서 기반한 것인데, 몇몇의 입력 이미지를 feature space에 encode 하고 fusion operation을 적용하는데, fusion operation은 metric-based few-shot learning에서의 comparison operation과 유사합니다. 그다음에 fused feature는 같은 카테고리의 이미지로 다시 decode 됩니다.
Fusion-based few-shot generation 의 핵심은 적은 conditional 입력과 이미지의 품질과 다양성을 유지하는 다양한 출력 사이의 label-consistent mapping을 구현하는 것입니다. GMN 은 Matching Network와 VAE 를 함께 사용하여 구현하였지만 숫자나 간단한 시각적 패턴을 생성하는 데 그쳤습니다. 이를 해결하기 위해 MatchingGAN 은 VAE 를 GAN으로 교체하여 자연스러운 이미지를 생성해 내는 데 성공했습니다만 복잡한 이미지를 처리하는 데는 어려움이 있었습니다. 최근의 F2GAN 은 fuse-and-fill 방법을 제안하여 성능을 향상했지만 여전히 제한되고 부정확한 생성 공간으로 인해 어려움을 겪었습니다. 이는 엄격한 linear combination과 weighted image-level reconstruction loss 가 원인입니다. 이 두 가지로 인해 이미지가 sematically aligned 되지 않았을 때 fused feature map 또한 misaligned 되고, 간단한 global combination으로 인해 생성할 때 다양성이 훼손됩니다.
이를 해결하고자 본 논문에서는 fusion-based few-shot image generation에서 local-fusion을 적용합니다. 여러 장의 이미지가 주어졌을 때, 한 이미지를 base image로 두고 나머지를 reference images로 둡니다. Base image을 generation의 basis로 두고 reference images는 사용 가능한 local represention의 역할을 하게 됩니다. Local fusion module에서 우선 base image에서 몇몇 local position을 무작위로 선택합니다. 그다음 reference images에서 의미상으로 적합한 local representation을 찾아내어 base image에 fuse 합니다. 그리고 본 논문에서는 학습 과정에서 local fusion module 잘 협조하기 위해 local construction loss를 제안합니다. 그로 인해 생성된 이미지가 입력 이미지의 local area에 유사하도록 합니다.
2. Related Work
2.1. Generated Adversarial Networks
Antreas et. al. 또는 Shengyu Zhao et. al. 에서는 적은 데이터 환경에서의 GAN을 연구했었습니다. 그러나 이런 방법은 unconditional 한 환경입니다. 본 논문에서는 conditional 한 환경에서 특정 novel category의 몇몇 이미지만 가지고 해당 category 의 이미지를 생성하는 것을 목표로 하였습니다.
2.2. Few-shot Generative Adaptation
몇몇 연구에서는 적은 학습 데이터를 가진 환경에서 이미지를 생성하기 위해 transfer learning을 도입했습니다. Transfer learning 을 적용하면 사전에 대용량의 데이터셋으로 학습을 한 후, 적은 데이터 도메인에 적응시킵니다. 이 경우, pre-train을 시킨 source domain과 target domain 은 disjoint 해야 합니다. 본 논문에서는 한 도메인에서 disjoint 한 label set을 구성하였습니다. 그다음의 별도의 fine-tuning을 거치지 않고 적은 label의 이미지를 생성하고자 합니다.
2.3. Few-shot Image Generation
Few-shot image generation의 목표는 몇몇 unseen category에 대해서 다양하고 현실적인 이미지를 생성하는 것입니다. 이를 위한 방법 중 optimization-based 방법인 FIGR과 DAWSON 은 adversarial learning과 MAML을 섞어 사용했습니다. 그러나 생성 품질의 한계가 있었습니다. Fusion-based 방법 중 GMN과 MatchingGAN 은 VAE 나 GAN을 이용하여 matching network를 few-shot classification에서 few-shot generation으로 generalize 했습니다. F2 GAN 은 MatchingGAN 에서 Non-local Attentional Fusion Module을 추가하여 이미지를 생성하기 위한 다른 level 의 feature 들을 서로 혼합하거나 채웠습니다. 그러나 F2GAN 은 생성된 이미지가 다양하지 못했고 품질이 좋지 못했습니다. 위 방법과는 다르게 본 논문의 방법은 deep features를 select, match, replace 하여 좀 더 fine-grained 하게 fuse 하고자 합니다. 그리고 local-based reconstruction loss를 사용하여 aliasing artifacts를 줄이고자 했습니다.
3. Our method
3.1. Overall Framework
이미지 데이터를 seen categories \(\mathbb{C}_s\) 와 unseen categories \(\mathbb{C}_u\) 로 나누었고, \(\mathbb{C}_s \cap \mathbb{C}_u = \emptyset\) 입니다. 학습 과정에서 수백 개의 k-shot generation task를 \(\mathbb{C}_s\) 에서 생성하고 모델에 학습시킵니다. 그다음 테스트 과정에서 \(\mathbb{C}_u\) 에서 한 category를 골라 이미지를 가져와 모델에 입력으로 주어 이미지를 생성하도록 합니다. 아래 그림은 본 논문의 전반적인 프레임워크를 나타낸 것입니다.

Generator는 conditional generator이고 encode E, decoder H, Local Fusion Module(LFM)으로 구성되어 있습니다. 입력 이미지는 k-shot에 맞추어 \(X=\{x_1,..., x_k\}\)로 표현됩니다. 입력 이미지는 encoder에 들어가 deep feature \(\mathcal {F}=E(X)\)를 추출합니다. 그다음 LFM은 \(\mathcal {F}\)과 random coefficient \(\alpha\)를 받아 semantically aligned fused feature \(\hat {\mathcal {F}}=LFM(\mathcal {F},\alpha)\)를 생성합니다. 그렇게 되면 decoder가 이미지를 복원하여 \(\hat {x}=H(\hat {\mathcal {F}})\)을 생성합니다. 입력 이미지 \(X\)와 생성된 이미지 \(\hat {x}\)는 discriminator에 입력되어 adversarial training을 수행하는 데 사용됩니다.
3.2. Local Fusion Module

k-shot generation task에서 encoder 가 추출한 feature map \(\mathcal {F}=E(X)\in\mathbb {R}^{k\times {w}\times {h}\times {c}}\)에서 각각의 \(w\times{h}\times{c}\) 텐서는 c-차원의 w x h 크기의 local representation으로 볼 수 있습니다. 그리고 본 논문에서는 k 개의 feature 중 하나를 무작위로 선택하여 \(f_{base}\)로 두고 나머지 k-1 개의 feature를 \(\mathbb{F}_{ref}\) 로 두었습니다. 전체 과정은 local selection, local matching, local replacement로 구성됩니다.
Local selection 과정에서는 \(f_{base}\)의 어떤 local representation 이 교체될 것인가를 정합니다. 무작위로 \(n=\eta\times{w}\times{h}\) 만큼의 local representation을 선택합니다. 여기서 \(\eta\in(0,1]\)입니다. 그 결과 n 개의 c-dimensional local representation \(\phi_{base}\)를 얻을 수 있게 됩니다.
Local Matching 과정에서는 \(\phi_{base}\) 를 교체할 \(\mathbb {F}_{ref}\)의 local representation을 찾습니다. 각각의 reference feature에 대해 아래 식으로 유사도를 계산해 similarity map M을 얻습니다.
\[M^{(i, j)}=g(\phi^{(i)}_{base}, f^{(j)}_{ref})\]
이때, \(i\in\{1,..., n\}, j\in\{1,..., h\times {w}\}\)이고, \(g\)는 cosine similarity를 사용했습니다. M을 통해 \(\phi_{base}\)의 각 위치에서 가장 유사한 local representation을 찾을 수 있고, 그것을 다음 단계에서 원래 local representation 과 교체하는데 사용합니다. 본 논문에서는 k-1 의 reference feature map 에서 가장 유사한 local representation 을 \(\Phi_{ref}\in {\mathbb {R}^{(k-1)\times {n}\times {c}}}\)로 표현했습니다. 그와 동시에 \(\phi_{base}\)와 \(\Phi_{ref}\)의 모든 위치를 기록하여 후의 local reconstruction loss를 계산하는 데 사용합니다.
Local Replacement 과정에서는 base와 reference local representation을 fuse 하여 \(f_{base}\) 에 원래 위치에 교체합니다. Local matching 의 결과 예를 들면 \(\phi^{(1)}_{ref} \in{\mathbb{R}^{(k-1)\times{c}}}\) 는 \(\phi^{(1)}_{base}\in{\mathbb{R}^c}\) 와 가장 유사한 local representation 을 갖고 있습니다. 우리는 이것과 random coefficient vector \(\alpha=[\alpha_1,...,\alpha_k]\)를 사용하여 아래 식을 통해 feature 들을 fuse 합니다.
\[\phi^{(t)}_{fuse}=\alpha_{base}\cdot {\phi^{(t)}_{base}}+\sum_{i=1,..., k, i\neq {base}}\alpha_i\cdot {\phi^{(i)}_{ref}(t)}\]
따라서 fused feature map \(\hat {F}\)가 생성됩니다.
3.3. Local Reconstruction Loss
기존의 연구들은 주로 weighted image-level recostruction loss를 사용했습니다. 그러나 이 경우엔 이미지의 weighted stack 이 aliasing artifact를 가질 수 있기 때문에 부적절한 supervision으로 이어질 수 있습니다. 그래서 본 논문에서는 local reconstruction loss를 제안합니다.
\[\mathcal {L}_{local}=\Vert\hat {x}-LFM(X,\alpha)\Vert\]

3.4. Objective Function
\(X\)를 입력 이미지, \(\hat {x}=G(X,\alpha)\)를 생성된 이미지, \(c(X)\)를 X의 label이라고 할 때, adversarial loss는 아래의 hinge version GAN loss를 사용했습니다.
\[\mathcal {L}^D_{adv}=\max(0,1-D(X))+\max(0,1+D(\hat {x}))\]
\[\mathcal {L}^G_{adv}=-D(\hat {x})\]
또한 classification loss를 ACGAN 의 loss 를 사용했는데, classification loss는 discriminator는 실제 이미지를 적절하게 분류하고, generator는 주어진 label을 유지하면서 이미지를 생성하도록 합니다.
\[\mathcal {L}^D_{cls}=-logP(c(X)\vert {X})\]
\[\mathcal {L}^G_{cls}=-logP(c(X)\vert {\hat {x}})\]
따라서 최종 objective는 아래와 같습니다.
\[\mathcal {L}_G=\mathcal {L}^G_{adv}+\lambda^G_{cls}\mathcal {L}^G_{cls}+\lambda_{local}\mathcal {L}^G_{local}\]
\[\mathcal {L}_D=\mathcal {L}^D_{adv}+\lambda^D_{cls}\mathcal {L}^D_{cls}\]
4. Experiments
4.1. Implementation
Encoder는 하나의 입력 conv block과 4개의 downsampling conv block으로 이루어져 있습니다. 각각의 block 은 Leaky-ReLU와 batch norm. 이 적용되어 있습니다. Decoder는 encoder와 대칭으로 구성되어있습니다. LFM을 적용할 feature의 크기는 8x8입니다. Discriminator는 FUNIT과 유사한 네트워크를 사용했습니다.
학습과 관련된 사항은 아래와 같습니다.
- Optimizer: Adam
- # of epochs: 50000 with lr=0.0001 another 50000 with lr linearly decayed to 0.
- Training time: 36 hours
- Other hyperparameters: \(\eta=0.5, \lambda^G_{cls}=\lambda^D_{cls}=1 \lambda_{local}=0.5\)
4.2. Evaluation Datasets
사용된 데이터셋은 아래와 같습니다.
- Flowers
- Animal Faces
- VGGFace
4.3. Baselines
본 논문의 방법과 비교할 baseline 은 아래와 같습니다.
- FIGR
- GMN
- DAWSON
- DAGAN
- MatchingGAN
- F2GAN
4.4. Quantitative Evaluation
Quantitative evaluation 은 3-way generation setting에서 진행됐습니다. 우선, 모델을 seen images로 학습시킵니다. 그다음, unseen category 를 \(\mathbb{S}_{in}, \mathbb{S}_{real}\) 의 두 파트로 나누는데, \(\mathbb{S}_{in}\)은 128장의 3-shot image generation task 를 구축하는 데 사용되어 각 카테고리마다 128 장의 이미지를 갖게 됩니다. 그 다음 생성된 이미지 \(\mathbb {S}_{gen}\)과 \(\mathbb {S}_{real}\) 사이의 FID와 LPIPS를 측정하여 성능을 평가합니다. 게다가 본 논문의 LFM의 효과를 보여주기 위해 MatchingGAN의 global fusion module을 LFM으로 교체하여 MatchingGAN†+LFM라고 표시했습니다. 결과는 아래와 같습니다.
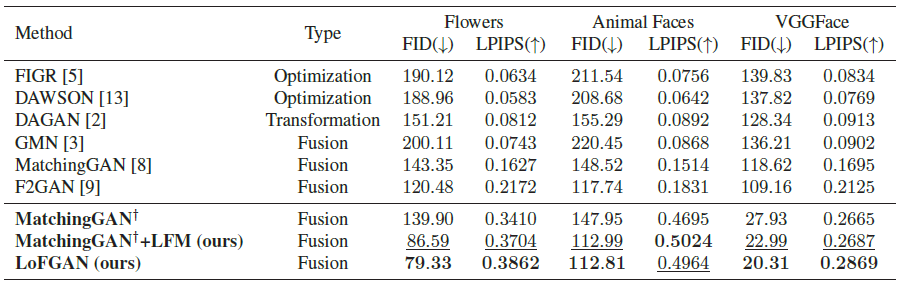
LFM 만 적용해도 성능에 큰 영향을 주었고, 본 논문의 LoFGAN처럼 LFM과 local reconstruction loss를 모두 적용하였을 때 가장 좋은 성능이 나왔습니다.

본 논문의 방법이 더 적은 artifact와 동시에 다양한 질감과 생상을 갖는 이미지를 생성했습니다.
4.5. Visualization of the Learned Similarity
모델이 다른 이미지에서 semantic similarity를 잘 학습하는지 확인하기 위해 base 이미지와 reference 이미지 사이의 similarity map을 시각화했습니다. Base 이미지의 다른 위치와 reference 전체 이미지 사이의 similarity map 을 시각화한 결과는 아래와 같습니다.

본 논문의 방법이 유사도를 적절하게 찾는 것을 확인할 수 있습니다.
4.6. Influence of the Selection Rate
이번에는 local selection 과정에서 \(\eta\) 값에 따른 성능의 변화를 실험해보았습니다.

\(\eta\) 값이 커짐에 따라 base image가 많이 변화하는 것을 확인할 수 있습니다.
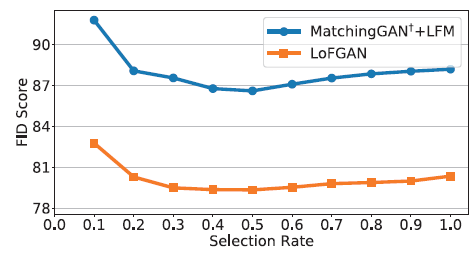
\(\eta=0.5\) 일 때, FID가 가장 적게 나왔습니다.
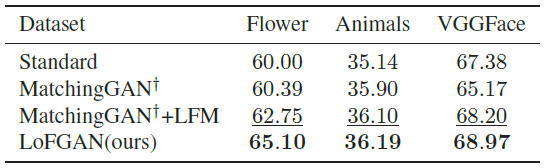
4.7. Augmentation for Classification
생성된 이미지를 classification에서 augment data로 사용할 수도 있습니다. 본 논문에서는 unseen categories를 \(\mathbb {D}_{train},\mathbb {D}_{val},\mathbb {D}_{test}\)로 나누었습니다. 그다음 ResNet18을 seen categories로 초기화하고 \(\mathbb {D}_{train}\)으로 새로운 classifier를 학습시켰고 이를 Standard로 명명했습니다. 그다음에 여러 few-shot generation 방법들을 이용하여 \(\mathbb {D}_{train}\)을 augment 하고 분류 성능을 측정했습니다.
4.8. Comparison of Different Numbers of Shots
이번에는 학습 데이터의 수에 따른 성능의 변화를 측정했습니다.
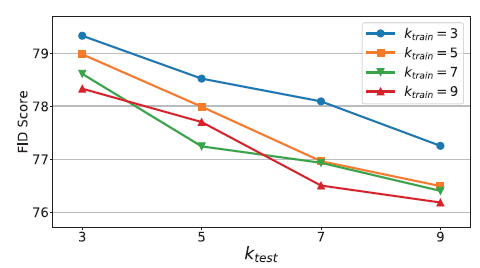
학습 데이터의 수가 많아지면 reference local represenation의 수가 많아지므로 base 이미지에 대해 다양한 fusion을 진행할 수 있게 됩니다. 그러고 그 결과, 실제로 shot의 개수가 많아질수록 성능은 향상된 것을 확인할 수 있습니다.
References
[2] http://proceedings.mlr.press/v84/bartunov18a/bartunov18a.pdf
[3] https://arxiv.org/abs/2003.03497



댓글