이번 포스팅에서는 Yulai Cong이 NeurIPS 2020에서 발표한 "GAN Memory with No Forgetting"을 읽고 정리해보도록 하겠습니다.
1. Introduction
Lifelong learning 또는 continual learning은 모델에게 새로운 지식을 학습시키는 것 입니다. 그 과정에서 기존에 학습했던 지식은 까먹어서는 안됩니다. 보통의 경우 새로운 task를 학습시키면 기존 task는 잊어버리기 쉬운데, 이런 현상을 catastrophic forgetting이라 하고, lifelong learning은 이 catastrophic forgetting을 해결하는 데 초점을 두고 있습니다.
Catastrophic forgetting을 해결하기 위해 classification task에서는 많은 연구들이 진행되어왔습니다. Revealed generative replay 또는 pseudo-rehearsal에서는 이전 task가 완벽하게 기억된다면 forgetting이 발생하지 않을 것이라 기대합니다. 그러나 기존의 replay-based 방법들은 다소 blurry한 이미지를 생성하거나 MNIST, SVHN과 같은 비교적 간단한 데이터에서만 적용되었습니다. 그리고 또한 고해상도나 task sequence가 길어질 경우 제대로 작동하지 않았습니다.
본 논문에서는 catastrophic forgetting을 완화하기 위해 realistic generative memory with growing power를 고안했습니다. 그 과정에서 일반적인 GAN setup을 사용했고 이를 GAN memory라고 칭했습니다. 그 근거로 GAN은 고차원의 sample을 다루는데 효과적이고, model parameter에서 statistical information을 요약하여 사용하기 때문에 original data에 대한 privacy 문제가 방지됩니다. 그리고, 종종 학습 데이터에 존재하지도 않는 이미지를 생성하기 때문에 downstream task에서 효과적일 수 있습니다.
본 논문의 GAN memory는 transfer learning과 style transfer를 적용하여 연속적인 task에서의 generative process를 no forgetting으로 기억하기 위해 well-behaved GAN을 연속적으로 변형합니다.
본 논문의 contribution은 아래와 같습니다.
- FiLM과 AdaFM에 기반한 mFiLM, mAdaFM를 새로 고안하여 source 도메인의 fc layer와 conv layer를 더 잘 adapt 또는 tranfer하게 하였습니다.
- 위에 기반하여 현재 수행 가능한 task의 forgetting 없이 task가 추가됨에 따라 더욱 표현능력이 향상되는 GAN memory를 제안하였습니다. 그리고 여기에 사용된 style parameter의 역할과 compressibility를 분석했습니다.
- GAN memory를 conditional variant로 일반화하여 lifelong classification task에서 realistic synthesized sample로 사용될 때의 효과를 보였습니다.
2. Related work
현존하는 lifelong learning의 방법은 regularization-based, dynamic-model-based, generative-replay-based의 3가지 방법으로 분류됩니다. 이 중, generative-replay-based 방법은 효과적이고 일반적인 방법이라고 평가되지만, 대부분 blurry하고 distort된 이미지를 생성하거나, scalability issue가 존재합니다. MeRGAN은 현재 generator의 사본을 이용하여 이전 data를 replay 하지만 그 이미지가 blurry합니다. CloGAN은 auxiliary classifier를 distorted replay의 일부분을 걸러내기 위해 사용하지만 어느정도 forgetting이 존재합니다. OCDVAE는 open-set recognition과 VAE-based generative replay를 합쳤지만 고해상도의 이미지에서 blurry generation이 존재합니다. DGMw는 shared generator를 기반으로 하여 task-specific binary mask를 도입하였지만, task sequence가 길어짐에 따라 문제가 발생했습니다. Lifelong GAN은 cycle consistency과 knowledge distillation을 적용했지만, 이전 task에 대해서 좋지 않은 성능을 보였습니다. 그러나 본 논문의 GAN memory는 forgetting 없이 현실적인 이미지를 생성하고 task sequence가 길어짐에도 불구하고 잘 작동합니다.
Generative tasks에서 transfer learning은 많이 연구되지 않았습니다. A. Noguchi et. al.은 GAN generator를 freeze하고 그 hidden layer의 statistics에 새로운 task의 statistics를 L1/perceptual loss로 adaptation하였습니다. M. Zhao et. al.은 AdaFM을 이용하여 적은 수의 target domain에서의 이미지를 생성하고자 하였습니다. 그러나 기존의 방법들은 모두 source domain에서의 이미지를 생성하는 데는 신경을 기울이지 않았으며, target domain은 blurry한 이미지를 생성했습니다. 본 논문의 GAN memory는 source generation을 유지한 채 target domain에 대한 realistic한 이미지를 생성할 수 있습니다.
3. Preliminary
이번 장에서는 본 GAN memory에 초석이 된 GAN과 style transfer를 짧게 리뷰합니다.
GAN은 아래의 objective function으로 적대적으로 학습됩니다.

이때 \(p(z)\) 는 Gaussian과 같은 간단한 확률 분포입니다.
Style transfer를 이용하면 이미지의 latent feature를 변형하는 것 으로 이미지의 style을 변형시킬 수 있습니다. 이러한 style-transfer 방법들에는 conditional instance normalization이나 adaptive instance normalization (AdaIN)이 있습니다. 대부분은 Feature-wise Linear Modulation (FiLM)과 관련이 있는데, FiLM은 latent feature에 간단한 element-wise affine transformation을 적용시켰습니다.
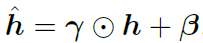
여기서 \(h\in\mathbb{R}^d\)이고 \(\hat{h}\)는 다음 layer에 입력으로 들어갑니다. scale \(\gamma\in\mathbb{R}^d\)와 shift \(\beta\in\mathbb{R}^d\) 입력 정보에 따라 달라지게 됩니다.
FiLM과는 좀 다른, adaptive filter modulation (AdaFM)은 conv layer에 대해 boosted transfer performance를 하기 위해 filter의 style을 변경합니다. source filter \(\mathbf{W}\in\mathbb{R}^{C_{out}{\times}C_{in}{\times}K_1{\times}K_2}\)에 대해 AdaFM은 다음 연산을 합니다.

여기서 scale matrix \(\Gamma\in\mathbb{R}^{C_{out}{\times}C_{in}}\)와 shift matrix \(\mathbf{B}\in\mathbb{R}^{C_{out}{\times}C_{in}}\) 그리고 modulated \(\hat{\mathbf{W}}\)는 입력 feature map과 output feature map을 convolve하기 위해 사용됩니다.
4. Proposed method
GAN memory는 task sequence \(\{\mathcal{D}_1,\mathcal{D}_2,...\}\) 를 순차적으로 학습하고 \(t\)번째 task에 대한 학습이 끝난 후 \(\{\mathcal{D}_1,...,\mathcal{D}_t\}\)와 닮은 이미지를 생성할 수 있어야합니다.
4.1. Surprising discovery
본 논문에서는 source domain의 generator와 discriminator style을 perceptually-distant한 target domain의 이미지를 생성하도록 변경할 수 있단 것을 발견했습니다. 이는, fc layer와 conv layer에 후술할 style-modulation techniques를 통해 조작하면서 이뤄집니다.
본 논문에서는 CelebA 데이터셋으로 학습된 GP-GAN을 source로 사용했습니다. 그리고 perceptually-distant dataset으로 Flowers, Cathedrals, Cats, Brain-tumor, Chest, Anime faces를 사용했습니다. Style-modulation 기법을 적용해보니 source domain이 매우 상이했음에도 불구하고 모든 target domain에서 realistic한 이미지를 생성해 낼 수 있었습니다. 바꿔서 말해보면 특정 target domain이 주어졌을 때, source domain은 유동적으로 선택할 수 있게 됩니다.
본 논문에서는 fc layer에 대한 style-modulation 기법으로 modified FiLM (mFiLM)과 conv layer에 대한 style-modulation 기법으로 modified AdaFM (mAdaFM) 을 제안했습니다. Source fc layer는 다음과 같이 구성되어있습니다. \(\mathbf{h}^{source}=\mathbf{W}z+\mathbf{b}\), 여기서 \(\mathbf{W}\in\mathbb{R}^{d_{out}{\times}d_{in}}, \mathbf{b}\in\mathbb{R}^{d_{out}}, z\in\mathbb{R}^{d_{in}}\)입니다. mFiLM은 이러한 parameter를 target function \(\mathbf{h}^{tatget}=\hat{\mathbf{W}}z+\hat{\mathbf{b}}\) 을 구성하기 위해 변형합니다:
\[\hat{\mathbf{W}}=\gamma\odot\cfrac{\mathbf{W}-\mu}{\sigma}+\beta, \hat{\mathbf{b}}=\mathbf{b}+\mathbf{b}_{FC}\]
여기서 \(\mu,\sigma\in\mathbb{R}^{d_{out}}\)은 벡터 \(\mathbb{W}\)의 각 원소의 평균과 표준 편차입니다. 그리고 \(\gamma, \beta, \mathbf{b}_{FC}\in\mathbb{R}^{d_{out}}\)는 각각 target-specific한 scale, shift, bias style parameter이고 target domain의 data로 학습 가능합니다.
Source conv layer가 \(\mathbf{H}^{source}=\mathbf{W}*\mathbf{H}'+\mathbf{b}\)로 표현될 때, mAdaFM은 \(\mathbf{H}^{target}=\hat{\mathbf{W}}*\mathbf{H}'+\hat{\mathbf{b}}\)의 target function로 변형합니다:
\[\hat{\mathbf{W}}=\Gamma\odot\cfrac{\mathbf{W}-M}{S}+B, \hat{\mathbf{b}}=\mathbf{b}+\mathbf{b}_{Conv}\]
이때 \(M, S\in\mathbb{R}^{C_{out}{\times}C_{in}}\)의 원소 \(M_{i,j},S_{i,j}\)는 \(\mathbf{W}_{i,j,:,:}\)에서의 각각 평균과 표준편차입니다. mFiLM과 유사하게 target-spefic parameter인 \(\Gamma, B\in\mathbb{R}^{C_{out}{\times}C_{in}}\)는 target 이미지에 맞춰 학습됩니다.
4.2. GAN memory to sequentially remember a stream of generative processes
GAN memory의 전반적인 구조는 아래와 같습니다.

Source GAN을 target에 맞춰 변형시킬 때, source model은 freeze하고 target-specific style parameter를 제한적으로 도입합니다. Style parameter들은 크게 scale, shift, bias의 3가지 그룹으로 묶입니다.

style parameter를 적용시키지 않았을 때는 source domain의 이미지가 생성되고

모든 style parameter를 적용시켰을 때는 target domain의 이미지가 생성됩니다. 그리고 scale parameter만 적용시켰을 때는

질감이나 구조적인 형태만 포착합니다. 그리고 shift parameter만 적용됐을 때는

target domain의 low-frequency color information만 control하게 됩니다. 마지막으로 bias parameter만 적용됐을때는

잘 포착되진 않지만 빛과 위치조정 정도만 나타났습니다. 그래서 bias의 효과를 확인해보고자 brain-tumor dataset에서 scale과 shift는 고정한 채 bias의 유무에 따른 이미지를 비교했습니다.

그 결과 bias parameter는 종양과 같이 위치가 중요한 데이터에서 필수적이라고 할 수 있습니다.
다른 block의 style parameter는 이미지 생성시에 strength와 focus가 다릅니다.

위 사진은 None에서부터 block의 style parameter를 하나씩 적용시킨 결과입니다. FC는 단순히 빛정도만 변화시켰고, B0~B3는 얼굴을 꽃으로 변화시켰습니다. B4~B6에서는 디테일한 부분을 다듬었습니다.
mFiLM과 mAdaFM에 대한 ablation study도 함께 진행되었습니다.
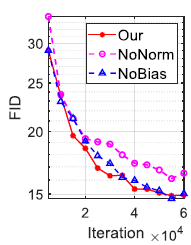
Normalization은 target domain의 style을 학습하는데 효과적이었고, bias를 통해 효율적인 학습이 가능해졌습니다.
GAN memory는 생성 과정에서 두개 이상의 style parameter를 조합하면서 smooth interpolation도 가능합니다.

위 사진은 flower와 cat 사이에 smooth interpolation을 적용시킨 결과인데 style parameter가 다양한 data augmentation으로 사용될 수 있음을 보여줍니다.
GAN memory는 쉽게 label-conditioned generation problem에 적용될 수 있습니다. Conditional GAN과 유사하게 클래스마다 하나의 fc bias를 지정했습니다. 그래서 style parameter는 아래와 같습니다.

새, 강아지, 나비에 대해 6가지 class의 이미지를 생성한 결과는 아래와 같습니다.

4.3. GAN memory with further compression
Task의 개수가 많아지면, 이런 style parameter를 모두 저장하는것은 부담이 될 수 있습니다. 그래서 이번 절에서는 style parameter가 보다 낮은 용량을 차지하도록 압축될수 있음과 task간에 shared parameter를 두어 메모리를 절약할 수 있음을 설명합니다.
본 논문에서는 다른 block/layer에서 학습된 \(\Gamma, B\)의 특잇값을 조사해보았습니다.

\(\Gamma, B\)가 일반적으로 low-rank를 갖는다는 점을 확인할 수 있습니다. 게다가, \(\Gamma\)와 \(B\)가 noise에 가까워 질 수록 low-rank가 더 두드러져 나타납니다. 이에따라, 작은 특잇값들을 0으로 처리하거나 잘라낸 다음에 성능의 저하가 얼마나 발생했는지 확인했습니다.

B0~B4에서는 80%정도 유지하는 것 만으로도 압축 전과 비교하여 비슷한 성능을 보였습니다.
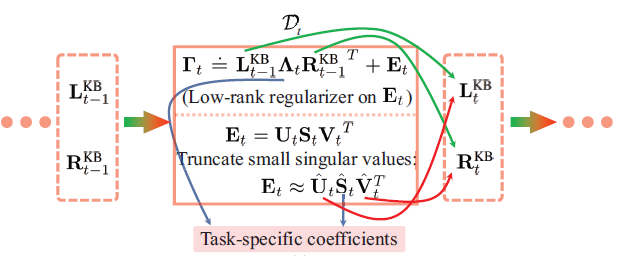
\(\Gamma, B\)의 압축가능성에 기반하여 본 논문에서는 task간의 parameter sharing을 제안했습니다. Parameter sharing은 matrix factorization과 low-rank regularization을 기반으로 하여 lifelong knowledge base mimicking을 구성했습니다. t번째 task에서 \(\Gamma_t\)를 직접적으로 최적화하는 대신에 아래 수식을 통해 최적화 시킵니다:
\[\Gamma_t=L^{KB}_{t-1}\Lambda_t(R^{KB}_{t-1})^T+E_t\]
여기서 \(L^{KB}_{t-1}, R^{KB}_{t-1}\)는 각각 이전 task의 left/right knowledge base이고, \(\Lambda_t=Diag(\lambda_t)\)이고 \(\lambda_t\)와 \(E_t\)는 각각 task-specific한 trainable parameters입니다. Nuclear norm \(\Vert{E_t}\Vert_*\)는 loss function에 low-rank property를 유지하기 위해 더해집니다. t번째 task에 대한 학습이 끝나고, \(E_t\)에 대해 SVD (Singular Value Decomposition)을 적용하여 상위 X%만큼의 특이값을 보존하여 압축을 합니다. 그리고 각각의 left/right singluar vector를 left/right knowledge base를 업데이트하는 데 사용하여 \(L^{KB}_{t}, R^{KB}_{t}\)를 얻습니다. 전체적인 과정은 아래와 같습니다.
5. Experiments
5.1. GAN memory on a stream of generation tasks
본 논문의 GAN memory를 기존의 replay-based method와 비교하기 위해서 6개의 perceptually-distant task를 구성했습니다. Task의 순서는 Flowers - Cathedrals - Cats - Brain-Tumor - Chest-X rays - Anime Face 순입니다. Backbone으로는 CelebA에서 pretrain된 GP-GAN을 사용했습니다. GAN memory는 MeRGAN과 비교되었는데, MeRGAN은 이전 task의 이미지를 생성하기 위해 generator의 복사본을 갖고 있습니다. GAN memory와 MeRGAN의 qualitative comparison의 결과는 다음과 같습니다.

MeRGAN은 이전 task의 이미지 생성이 다소 blurry하게 나오는 반면에 GAN memory는 forgetting 없이 이미지가 생성된 것을 알 수 있습니다. Quantitative comparison 결과는 아래와 같습니다.
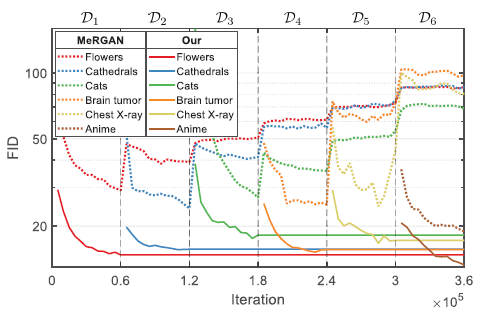
MeRGAN은 iteration이 진행됨에 따라 FID가 증가하는걸로 보아 forgetting이 발생했지만, GAN memory는 forgetting이 발생하지 않았습니다.
5.2. Conditional-GAN memory as pseudo rehearsal for lifelong classifications
이번에는 GAN memory를 lifelong classification task에서 pseudo rehearsal로 활용하였습니다. 각각 6가지의 클래스로 구성된 6개의 task (물고기 - 새 - 뱀 - 개 - 나비 - 곤충)을 구성했습니다. 실험은 class-incremental learning setup에서 진행됐는데, t번째의 task에서 학습을 마치고 classifier는 6t개의 class를 모두 분류할 수 있어야합니다. 비교를 위해 regularization-based 방법인 EWC와 replay-based 방법인 MeRGAN을 사용했습니다. 학습 과정에서는 현재 task의 데이터와 replayed data를 함께 사용했습니다. 결과는 아래와 같습니다.
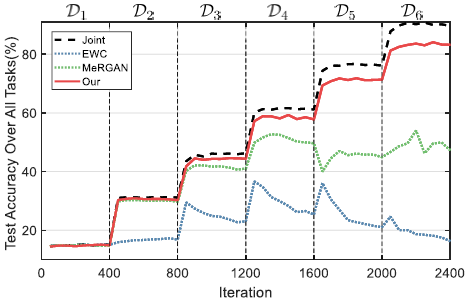
여기서 joint는 upper-bound로, 생성된 historical 데이터가 아닌, 실제 historical 데이터와 현재 task의 데이터를 함께 사용한 것입니다. GAN memory는 upper-bound에 근접한 성능을 보여주었습니다.
5.3. GAN memory with parameter compression and sharing
4.3절에서 서술한 parameter compression의 효과를 알아보기 위해 6개의 나비 카테고리로 구성된 task sequence를 설정했습니다. 실험 결과는 아래와 같습니다.
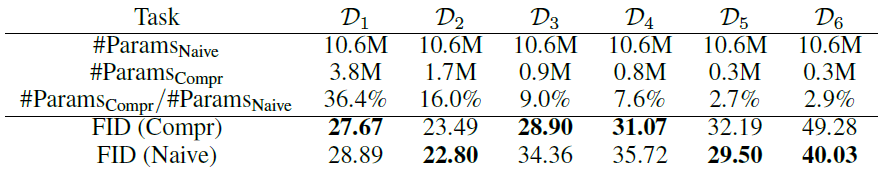
Knowledge base가 없는 \(mathcal{D}_1\)의 경우에도, \(\Gamma,B\)의 low-rank property가 상당한 parameter compression으로 이어진다는것을 확인할 수 있습니다. 그리고 적은 수의 새로운 parameter만으로도 새로운 task에서 generation을 가능하게 합니다. 그리고 parameter compression을 하더라도 naive에 비해 성능저하는 크게 발생하지 않았습니다.
6. Conclusions
본 논문에서는 GAN 모델의 style을 변경하는 것 만으로 perceptually-distant한 target의 이미지를 정확하게 합성할 수 있다는 것을 밝혔습니다. 이에 기반하여 본 논문에서는 forgetting이 발생하지 않으며 generation power가 증가하는 GAN memory를 제안했습니다. 그리고 새로운 compression 기법을 제안하고 다른 방법들에 비해 장점들을 확인했습니다.
References
[1] https://arxiv.org/abs/2006.07543
[2] https://arxiv.org/abs/1904.01774
[3] https://arxiv.org/abs/2002.11810
[4] https://arxiv.org/abs/1709.07871
[5] https://www.secmem.org/blog/2019/06/15/matrix-decomposition/


댓글