이번 포스팅에서는 Utkarsh Ojha가 CVPR 2021에서 발표한 "Few-shot Image Generation via Cross-domain Correspondence"를 읽고 정리해 보도록 하겠습니다.
1. Introduction
현대의 생성 모델들은 대부분 FFHQ나 ImageNet과 같이 대용량의 데이터셋에서 학습이 진행됐습니다. 그러나 예술 도메인과 같이 실제에 많은 케이스에서는 앞서 언급한 데이터셋만큼 많은 데이터를 확보할 수가 없습니다. 이러한 few-shot 환경에서도 좋은 데이터를 생성하기 위해 transfer learning을 적용할 수 있습니다. Transfer learning은 큰 규모의 source domain에서 학습시킨 모델을 데이터의 수가 적은 target domain에 adaptation하는 것입니다.
본 논문에서는 이미지가 서로를 어떻게 연관 짓는 지를 중점으로 source domain에서 few-shot setting의 target domain으로 transfer learning을 시도했습니다. 만약에 모델이 source domain에서의 similarity와 differnce를 유지할 수 있다면 target domain에 adapt할 때 diversity가 보존된다고 합니다. 그래서 본 논문에서는 cross-domain distance consistency loss(CDC)를 제안하여 adaptation 전후로 생성된 이미지 간의 distance를 유지시켰습니다.
이때 source와 target이 유사하다면(사람 얼굴과 캐리커쳐), 본 논문의 방법이 자동으로 1대1의 상관성(correspondence)을 찾고, diversity와 realism을 동시에 만족하면서 target domain의 distribution을 잘 따라갑니다. 만약에 자동차와 캐리커쳐처럼 두 도메인이 유사하지 않다면 target distribution을 잘 표현하진 못하지만 부분적인 correspondence는 유지가 되어 diverse한 이미지를 생성합니다.
그리고 학습 이미지가 target domain distribution의 극히 일부에 지나지 않는다는 점에 착안하여, image-level loss와 patch-level loss를 latent space 상의 anchor region에 속하는 지 여부에 따라 다르게 적용했습니다.
2. Related Work
Few-shot learning
대표적인 few-shot classification 방법들은 query와 support example 사이의 feature similarity를 학습시키는 방법과 base-learner를 new task에 어떻게 adapt할 지 학습시키는 방법으로 나뉩니다. 이와는 다르게 few-shot image generation은 오버피팅을 방지하는 동시에 새롭고 다양한 이미지를 생성하는 것에 집중합니다. 현존하는 방법들은 adpatation pipeline을 따르고 있습니다. 보통 파라미터를 source model에 추가하거나(BSA, MineGAN), regularization을 통해 source model의 weight를 업데이트하는 방법(EWC(리뷰))이 있습니다. 본 논문에서는 image간의 관계를 가지고 regularize 합니다.
Domain translation
보통의 domain translation(Pix2Pix,CycleGAN) 방법들은 많은 양의 데이터를 필요로 합니다. 이런 방법들은 few-shot scenario에 적합하지 않습니다. 그러나 FUNIT, SEMIT, COCO-FUNIT 처럼 최근의 방법들은 content와 style factor를 분리시키는 법을 학습시키면서 few-shot scenario에서 다뤄지기 시작했습니다. 그러나 이러한 방법들 또한 많은 class 또는 style label과 같은 labeled 데이터가 많이 필요하게 됩니다. 본 논문의 방법은 source domain의 수많은 unlabeled data에 접근하여 unconditional image generation하기 위해 adapatation을 진행합니다.
Distance preservation
Mode collapse를 완화하기 위해, DistanceGAN에서는 input pair와 corresponding generated output간의 distance를 유지시켰습니다. 비슷한 방법이 unconditional GANs(Shaohui Liu et al.)과 conditional GANs(Dingdong Yang et al.)에서도 적용되어 diverse한 image가 생성되었습니다. 본 논문에서는 source domain으로부터의 learned diversity를 target domain에 cross-domain distance consistency를 통해 inherit했습니다.
3. Approach
Non-saturating objective를 이용한 GAN의 학습은 아래 식에 의해 이루어집니다.
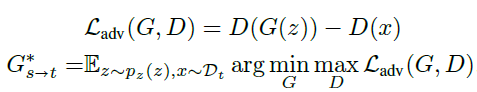
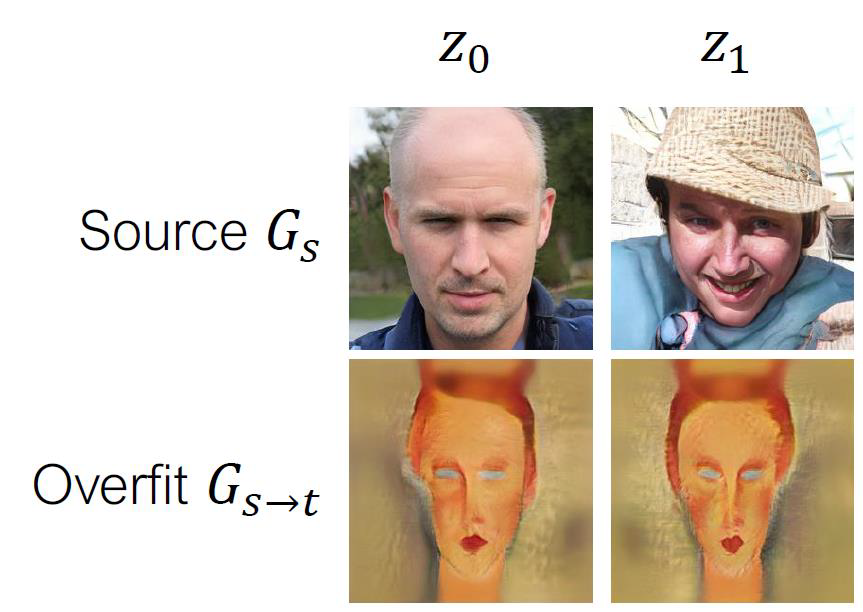
이때, 아주 적은 수의 target domain 데이터만 주어진다면, 위 방법을 그대로 적용했을 때 심각한 overfitting이 발생하게 됩니다. Image generation에서 overfitting이 발생하게 되면 아래 그림과 같은 결과가 나오게 됩니다.

위 그림에서 다른 noise vector에도 불구하고 source generator G_s는 다른 이미지를 생성하는 반면에, ovefitted된 genetator는 같은 이미지를 생성합니다. 이러한 문제를 해결하기 위해 본 논문에서는 3.1절에서 cross-domain distance consistency와 3.2절에서 relaxed discriminator를 설명합니다.
3.1 Cross-domain distance consistency
오버피팅된 결과를 낸 위 사진을 다시 봐 봅시다.
Source generator가 z_0, z_1에 대해 생성한 두 이미지는 겉보기에도 매우 다르게 생겼습니다. 그러나 오버피팅된 adapted generator는 겉보기에 비슷한 이미지를 생성했습니다. 이를 본 논문에서는 z_0과 z_1의 distance가 adaptation 전후로 붕괴했다고 합니다. 그래서 이러한 distance를 adaptation 전후로 유지시켜준다면, 다시 말해서 source generator의 distance를 adapted generator에서도 유지시켜 준다면 위 사진과 같은 결과가 나오는 것이 아니라, 아래 사진고 같은 결과가 나올 것이라고 가정합니다.
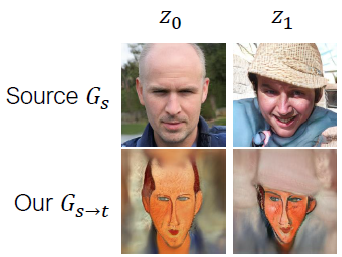
그를 위해 본 논문에서는 noise vector들의 batch를 여러 개 구성하고, 그런 batch들에서 생성된 이미지들 간의 similarity를 계산합니다. 아래 사진은 z_0을 기준으로 한 것입니다.
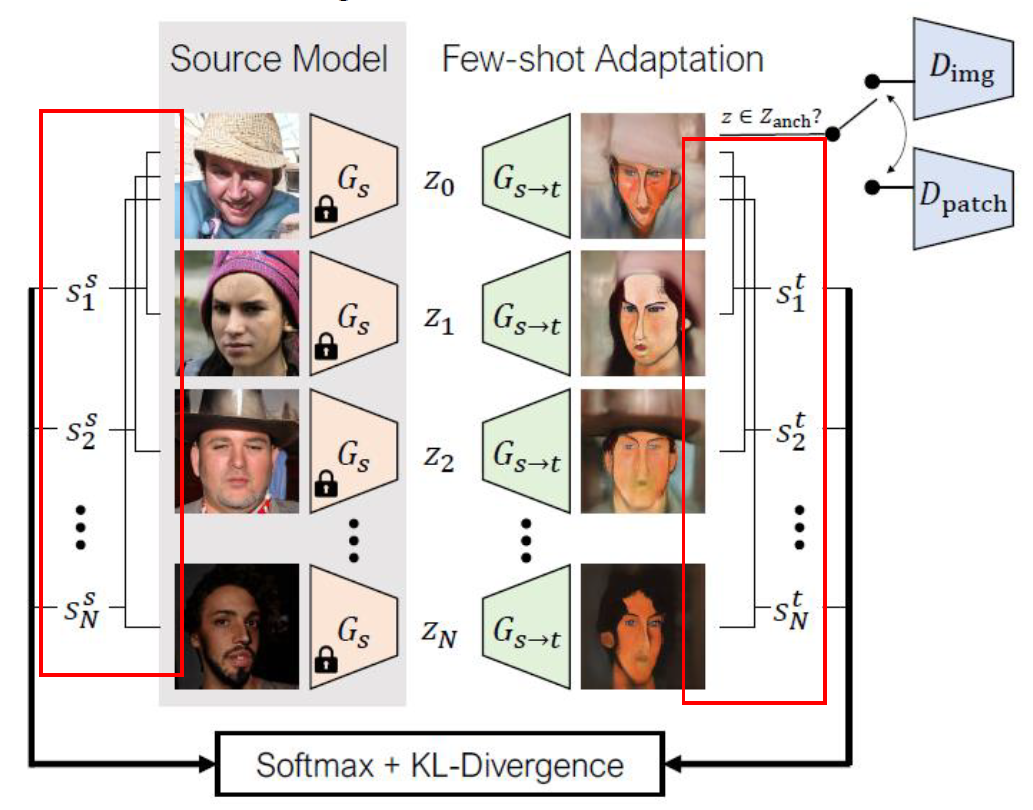
Source domain에서 z_0과 z_1간의 similarity s^s_1, z_0과 z_2간의 similarity s^s_2, ...
target domain에서 z_0과 z_1간의 similarity s^t_1, z_0과 z_2간의 similarity s^t_2, ...으로 하여 similarity를 계산합니다. 이때, similarity는 cosine similarity로 계산됩니다. 그러면 아래 식처럼 softmax를 이용하여 network의 layer l에서의 확률 분포를 추정할 수 있습니다.
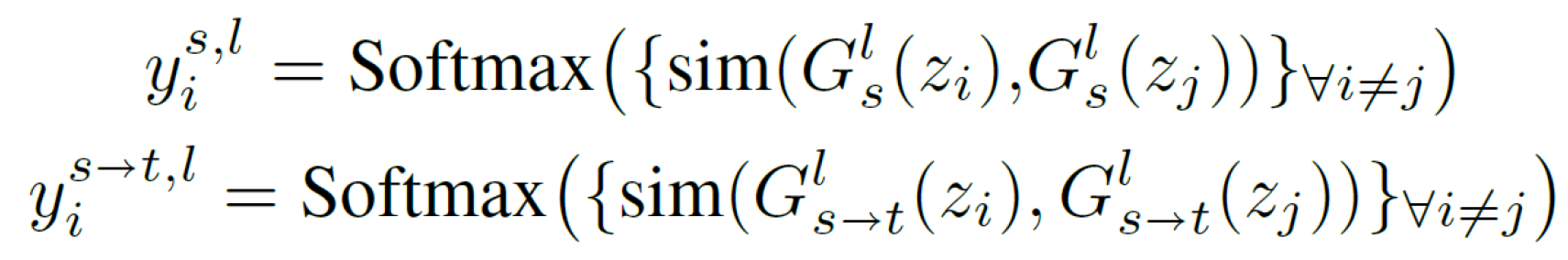
그런 다음 두 확률분포 간의 KL-Divergence를 계산하면 두 adapation 전후로 확률 분포의 차이를 계산할 수 있고 그렇게 하여 L_dist를 얻을 수 있습니다.

이를 cross-domain distance consistency loss라고 합니다. 이는 3.3절에서 소개될 Final objective에서 regularizer로 사용됩니다.
3.2 Relaxed realism with few examples
본 논문에서는 몇몇의 target domain의 데이터가 전체 target distribution의 일부에 지나지 않는다는 것에 주목했습니다. 그래서 전체 latent space에서 training image의 수만큼 랜덤으로 지점을 잡습니다. 이를 본 논문에서는 anchor region이라고 합니다. 실제로는 이러한 anchor region에 약간의 gaussian noise를 추가하여, anchor region에 속하는 noise vector에는 image-level adversarial loss를 적용하고, 그 외의 noise vector에는 patch-level adversarial loss를 적용합니다.
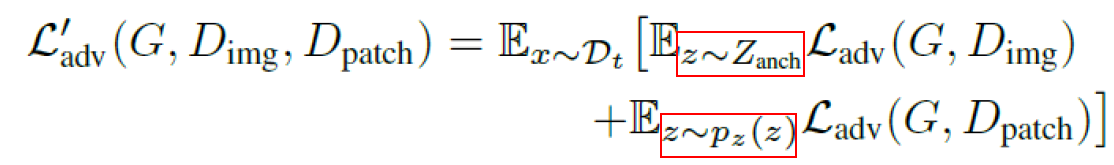
수식으로 표현하면 위와 같은데, 이를 본 논문에서는 relaxed realism이라고 합니다. 이때 image-level discriminator D_img와 patch-level discriminator D_patch는 weight를 공유합니다.
3.3 Final objective
따라서 cross-domain distance consistency과 relaxed realism을 모두 적용한 final objective는 아래와 같습니다.
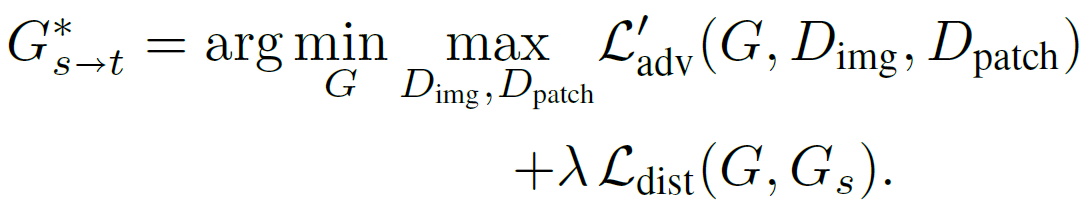
본 논문에서는 FFHQ dataset으로 pretrain된 StyleGANv2를 사용했고, batch size는 4, λ는 1000과 10000 사이의 수로 지정했습니다.
4. Experiments
실험에 사용된 baseline은 다음과 같습니다.
- TGAN
- BSA
- MineGAN
- Freeze-D
- TGAN+ADA
- EWC
실험에 사용된 데이터셋 중 source domain에 사용된 것은 다음과 같습니다.
- FFHQ
- LSUN Chruch
- LSUN Cars
- LSUN Horses
그리고 target domain으로는 다음 데이터셋이 사용되었습니다.
- Face caricatures
- Sketches
- Amedeo Modigliani의 초상화
- FFHQ-babies
- FFHQ-sunglasses
- 풍경화
- 흉가 이미지
- Van Gogh의 그림
- 폐차 이미지
4.1 Quality and Diversity Evaluation
첫 번째로 진행한 것은 qualitative study입니다. FFHQ를 source domain으로 하고, target domain으로 face caricatures, sketches를 사용했습니다. 결과는 아래와 같습니다.

실험 결과 TGAN은 overfitting이 발생했음을 알 수 있습니다. TGAN에 ADA를 적용한 것도 큰 효과를 보진 않았습니다. 심지어 캐리커처의 경우 augmentation이 generated image에 새어나가 더 심각한 품질 저하를 초래했습니다. Freeze-D, MineGAN, EWC는 TGAN에 비해 더 다양한 이미지를 생성했습니다. 그러나 이런 diversity는 매우 사소했습니다. 그에 반해 본 논문의 방법은 다양하고 현실적인 이미지를 생성했으며, target domain의 input에 해당하지 않는 이미지도 생성했습니다.
두 번째로는 quantative study가 진행되었습니다. 이때, 생성된 image의 quality는 FID(Frechet Inception Distance,↓)를 이용하여 측정되는데 그를 위해 target domain의 전체 데이터를 사용했습니다. 결과는 아래와 같습니다.
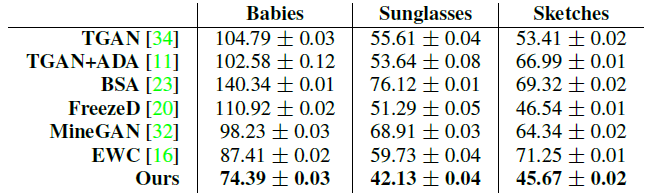
이 FID는 제가 따로 reproduce 해 보았는데 본 논문에서는 몇 장의 generated image를 이용해 측정했는지 명시되지 않아 전체 target domain의 수 대로 sampling하여 측정했습니다. Babies는 2492장, sunglasses는 2683장, sketches는 290장의 이미지를 사용했습니다. 그 결과 Babies에서는 77.75, sunglasses에서는 44.77, sketches에서는 53.07이 측정되었습니다. 본 논문의 결과와 다소 차이가 있긴 하지만 여전히 다른 baseline보다 더 좋은 품질의 이미지를 생성한다는 것을 확인할 수 있습니다.
그리고 이번엔 diversity를 측정하기 위해 intra-cluster LPIPS를 측정했습니다. 측정 방식은 다음과 같습니다. 우선 1000장의 이미지를 생성하고, 이런 이미지를 가장 LPIPS가 낮은 training image를 중심으로 하여 클러스터링합니다. 그다음 각각의 클러스터에서 각 이미지와 중심까지의 평균 거리를 측정하고 이를 전체 클러스터에 대해 평균을 냅니다. 그 결과는 다음과 같습니다.
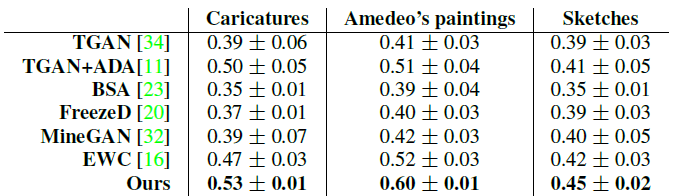
본 논문의 방법이 intra-cluster LPIPS가 가장 높게 측정되어 더 다양한 이미지가 생성됐음을 알 수 있습니다.
세 번째로 진행된 것은 ablation study입니다.

위 사진은 본 논문의 방법에서 cross-domain distance consistency loss를 적용하지 않았을 때의 결과입니다. 생성된 이미지들 간의 diversity가 줄어든 것을 볼 수 있습니다.

이번에는 L_dist와 image-level discriminator만을 적용했을 때의 결과입니다. Mode collapse가 부분적으로 발생하기도 했고, 생성된 이미지들 간의 약간의 변화 정도만 생겼습니다.

마지막으로 L_dist와 patch-level discriminator만을 적용했을 때의 결과입니다. Diversity는 이전 결과에 비해 보존되었지만 quality가 많이 떨어졌습니다.
4.2 Analyzing source ↔ target correspondence
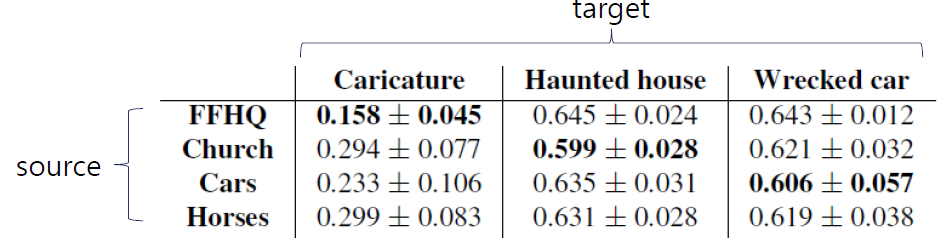
이번에는 여러 source/target domain pair에 대해서 실험을 진행했습니다. 첫 번째로는 서로 연관된 도메인들 사이에서의 실험입니다.

비슷한 도메인 간의 adaptation에서는 correspondence가 분명하게 나타났습니다. 그에 반해 관련 없는 도메인들 사이의 실험에서는

위 사진처럼 correspondence가 분명하게 나타나지는 않았습니다. 그러나 아래 사진처럼 부분적인 correspondence는 나타났습니다.

그다음에 다른 source domain에서 학습된 모델들이 새로운 input에 대해서 어떤 이미지를 생성하는지 보았습니다.

앞선 예시와 마찬가지로 source와 target domain이 관련 있을수록 더 자연스러운 이미지가 생성되었고 LPIPS를 측정해 보았더니 마찬가지의 결과가 나왔습니다.
4.3 Effect of target dataset size
이번에는 데이터셋의 사이즈에 따른 실험을 진행했습니다.

학습 데이터의 수가 많아질수록 더 다양하고 고품질의 이미지가 생성되었습니다.
5. Conclusion and Limitation
본 논문에서는 cross-domain correspondence를 찾아내어 pretrained GAN을 학습 데이터의 수가 적은 target domain에 적응시키고자 했습니다. 그러나 본 논문의 방법 또한 한계가 존재합니다.

위 이미지의 왼쪽은 LSUN Cars->wrecked/abandoned cars, 오른쪽은 FFHQ->FFHQ-sunglasses로의 adaptation을 진행한 것입니다. 왼쪽의 경우 같은 noise vector이지만 학습 데이터에 빨간색 차가 없기 때문에 주황색으로 표시되었고, 오른쪽의 경우 학습 데이터에 어두운 머리가 많아 머리가 어둡게 변화했습니다.
그럼에도 불구하고 data-efficient generative model에 중요한 기여를 했고, 현존하는 source model이 적은 양의 데이터로도 새로운 distribution을 잘 표현하는 것을 보여줬습니다.
References
[1] https://arxiv.org/abs/2104.06820
[2] https://github.com/utkarshojha/few-shot-gan-adaptation




댓글