이번 포스팅에서는 GoogLeNet이라고 알려져 있는 Christian Szegedy가 CVPR 2015에서 발표한 "Going Deeper with Convolutions" 를 읽고 리뷰해 보도록 하겠습니다.
GoogLeNet은 본 논문에서 소개될 Inception 모듈의 한 형태(incarnation)이며, ILSVRC 2014에서 top-5 error 6.67%로 우승을 차지했습니다.
1. Introduction
최근 3년간(2012~2015) CNN 분야는 급속도로 발전해 왔습니다. 이러한 발전은 대개 하드웨어의 발전뿐만 아니라 주로 네트워크 구조에 대한 기발한 아이디어가 원인입니다. 본 논문에서 소개될 GoogLeNet은 AlexNet에 비해 12배 작은 파라미터를 가지면서 더 정확한 성능을 냈습니다.
GoogLeNet에서 주목할 만한 점은 본 논문에서는 전력과 메모리 사용을 효율적으로 설계하여 모바일이나 임베디드 환경에 적용시킬 수 있게 한 것입니다. GoogLeNet은 inference시에 합곱(multiply-adds) 연산 횟수를 15억 번 이하로 지정하여 단순히 학문적 호기심이 아닌 실제로 적용시킬 수 있게 하였습니다.
GoogLeNet을 이루는 Inception 모듈은 Lin et al.에서 유래했습니다. 본 논문의 제목에서 deep는 두 가지 의미를 가집니다. 첫번째론 Inception 모듈이라는 새로운 형태의 구성을 제안한 것이고, 두번째론 말 그대로 매우 깊은 network를 의미합니다.
2. Related Work
Seere et al.은 primate visual cortex의 신경과학적 모델에 영감을 받아 여러 가지 scale을 다루기 위해 다른 사이즈의 Garbor Filter를 연속으로 사용했습니다. 이는 본 논몬에서 소개될 Inception model과 유사합니다. 그러나 Seere et al.은 고정된 2개의 layer를 사용했지만, Inception의 모든 필터들은 trainable합니다. 게다가 layer들은 여러 번 반복되고, GoogLeNet의 경우 22개의 layer로 구성되어 있습니다.
Network-in-Network(NiN)은 neural network에서 표현능력을 향상시키기위해 Lin et al.에의해 제안되었습니다. 이 방법이 conv layer에 적용될 때, 이런 방법은 1x1 conv에 ReLU를 적용시킨 것과 같습니다. 그래서 현재 CNN 파이프라인에 적용시키기 쉽고, 본 논문에서는 이를 많이 적용시켰습니다. 본 논문의 1x1 conv는 두가지 목적으로 사용되었습니다. 가장 중요한 첫번째는 computational bottleneck을 해결하기 위한 dimension reduction으로 작용하였습니다. 두번째로, 성능의 심각한 저하 없이 network의 깊이와 너비를 증가시킬 수 있게 되었습니다.
현재 object detection분의 선두는 Girshick et al.의 R-CNN입니다. R-CNN은 전반적인 detection 문제를 두 단계로 나누었습니다. 하나는 color과 superpixel의 consistency로 potential object proposal을 하는 것이고, 다른 하나는 이러한 위 치에 해당하는 카테고리로 분류하는 것입니다. 이러한 두 단계는 bounding box segmentation의 정확도와 CNN의 분류 능력에 기반합니다. 본 논문에서는 multi-box prediction으로 더 좋은 object box recall을 얻었고, 이러한 box를 예측하기 위해 ensemble을 적용시켰습니다.
3. Motivation and High Level Considerations
Deep neural network의 성능을 향상시키기 위한 가장 간단한 방법은 depth, the number of levels, width, the number of units를 늘리는 것입니다. 그러나 이러한 접근은 두 결점이 존재합니다. 첫번째로, 사이즈가 커진다는 것은 보통 오버피팅을 야기합니다. 데이터의 수를 늘리면 해결될 문제지만, 비용 문제로 한계가 존재합니다. 두번째로, 균등하게 증가된 network는 컴퓨팅 자원을 더 많이 잡아먹습니다.
이러한 문제를 모두 해결하기 위한 근본적인 방법은 fc layer를 sparsely connected한 구조로 변경하는 것입니다. Arora et al.에 따르면, 아주 거대한 sparse deep neural network으로 데이터셋의 확률 분포가 표현 가능하다면, 최적의 네트워크는 마지막 layer의 activation의 correlation statistics를 분석하고 highly correlated output으로 묶으면서 구성할 수 있다고 합니다. 물론 수학적으로 엄격한 상황은 아니지만, Hebbian principle과 일치하는 것에서 보이듯이 실제 상황에서도 적용할 수 있다고 합니다.
현대의 컴퓨팅 인프라는 non-uniform sparse structure에 lookup에 대한 오버헤드와 cache miss로 인해 다소 비효율적인 모습을 보입니다. 따라서 본 논문에서는 sparse matrix를 상대적으로 dense한 여러 개의 matrix으로 나누었습니다.
Inception은 Arora et al.의 sparse network를 사용 가능한 component로 구현하여 Arora et al.의 가설을 따라 가는지 보고자 하는 case study로 시작되었습니다. 두번의 반복 만에 NiN을 기반으로 한 아키텍처보다 조금 나은 성능을 보이는 구조를 찾아냈고 learning rate와 hyperparameter, training methodology를 조절한 후에 Grishick et al., Erhan et al.에 기반한 object dectection, localization에서 쓸만한 성과를 냈습니다.
4. Architectural Details
Inception의 메인 아이디어는 convolutional vision network에서 최적의 local sparse 구조를 어떻게 하면 현재 사용 가능한 dense component로 구성할지에서 기반했습니다. 본 논문의 Inception에서는 편의를 위해 filter size를 1x1, 3x3, 5x5로 제한했습니다. Inception은 이러한 layer들이 모여 next stage의 입력으로 들어가게 됩니다. Pooling이 CNN의 성공에 있어 필수 요소기 때문에, 1x1, 3x3, 5x5 conv layer에 이어 pooling도 추가했습니다.
이러한 Inception 모듈은 점점 위로(output과 가까이) 쌓이게 됩니다. 고차원의 특징들은 output에 가까워질수록 잘 포착되기 때문에 spatial concentration은 감소하기 마련입니다. 그래서 3x3와 5x5 conv layer의 비율을 output에 가까워 질 수록 늘려야 하는데, 이는 연산량의 증가로 이어집니다. 연산량의 증가는 pooling layer를 적용시켰을 때, 입력과 출력의 필터(채널) 수는 유지가 됩니다. Inception 모듈에서 pooling layer의 출력을 다른 layer의 출력과 함께 concatenate할 때 필터의 수가 오히려 Inception 모듈의 입력에 비해 증가가 되고, 더욱 심한 연산량 증가로 이어집니다. 그에 본 논문에서는 기존 방식을 naive 버전이라 칭하고, 새로운 버전의 Inception 모듈을 만들었습니다.

새로운 버전의 Inception 모듈은 1x1 conv를 제외한 각각의 conv layer 앞에, pooling layer에는 뒤에 1x1 conv를 적용시켜 dimension reduction 효과를 보게 했습니다. 그래서 보통은 위 사진의 오른쪽 Inception module with dimension reduction을 때때론 max pooling에 stride 2로 하여 사용했습니다. 메모리 효율 문제로 모델의 초반엔 기존의 CNN의 방식을 따르고 이후엔 Inception 모듈을 쌓아 사용했습니다. 그 결과 3x3과 5x5와 같이 큰 patch에서의 conv 연산을 진행기 전에 연산량 감소가 이루어졌고, 여러크기의 patch에서 얻은 출력으로 인해 여러 스케일에서 동시의 특징을 추출할 수 있게 됐습니다.
5. GoogLeNet
본 논문에서는 ILSVRC 2014 대회에서 Yann LeCun의 LeNet-5를 오마주로한 GoogLeNet을 팀명으로 삼았습니다. 또한 GoogLeNet은 Inception 모듈들의 한 형태(incarnation)입니다. Inception 모듈들을 더 깊게, 더 넓게 구성해 보았지만 오히려 성능은 살짝 떨어졌습니다. 대신에 ensemble에 함께 적용했을 때 성능이 살짝 향상되었습니다.
위 표는 GoogLeNet의 구성을 나타낸 것입니다. 실험에서는 이 GoogLeNet을 샘플링 기법만 달리 한 채 ensemble하여 적용했습니다. 모든 conv에는 ReLU가 포함되어있습니다. 본 모델의 입력은 224x224의 mean-subtracted RGB 이미지입니다. #3x3 reduce와 #5x5 reduce는 3x3 conv와 5x5 conv이전에 사용된 1x1 conv의 필터의 수 입니다. pool proj는 max-pooling 이후의 1x1 conv layer의 필터의 수 입니다. 모든 reduction과 projection 또한 ReLU가 적용되어 있습니다.
Network가 깊어지면서 gradient를 효율적으로 역전파시키는 것은 중요한 문제가 되었습니다. 이에 GoogLeNet에서는 auxiliary classifier를 network의 Inceptaion 4a와 Inception 4d 뒤에 추가했습니다. 학습중에는 auxiliary classifier의 출력의 0.3을 곱해서 전체 loss에 더해지고, 테스트 시에는 아예 auxiliary classifier를 사용하지 않습니다.
Auxiliary classifier는 다음요소들로 구성되었습니다.
- Inception 4a와 Inception 4d 뒤에 5x5, stride 3인 average pooling
- 필터의 수가 128인 1x1 conv layer 및 ReLU
- 유닛의 개수가 1024개인 fc layer 및 ReLU
- p=0.7의 dropout
- 유닛의 개수가 1000개인 fc layer
GoogLeNet의 전체적인 모습은 아래와 같습니다.
6. Training Methodology
GoogLeNet은 DistBelief를 통해서 학습되었습니다. 학습은 다음과 같이 진행되었습니다.
- Optimizer: Asynchronous SGD with 0.9 momentum
- Learning rate schedule: decrease the lr by 4% every 8 epochs
- Use Polyak averaging to create the final model at inference time
GoogLeNet에서 image sampling method는 매우 자주 바뀌었습니다. 그러나 이러한 변경이 dropout, learning rate 또는 다른 hyperparameter의 변경과 같이 이루어졌기 때문에 가장 효율적인 image sampling method를 설명하긴 어렵다고 합니다. 그러나 competition 이후 효과적이라고 보여진 것은, 전체 이미지에서 [8%,100%] 범위에서 여러 크기의 image 패치를 사용하고 가로와 세로의 비가 3/4에서 4/3사이에 적용시킨 것 입니다. 또한, Howard의 photometric distortion으로 오버피팅을 줄였습니다.
7. ILSVRC 2014 Classification Challenge Setup and Results
ILSVRC 2014 classification task에 사용된 방법은 다음과 같습니다.
- GoogLeNet의 7가지 버전을 학습시켜 ensemble 했습니다. 이러한 버전은 sampling 방법의 차이와 입력 이미지의 순서에만 차이가 있습니다.
- 테스트시에는 우선 가로와 세로 중 작은쪽이 256, 288, 320, 352가 되도록 이미지를 4개의 scale로 resize했고, 왼쪽, 오른쪽, 가운데의 3곳에서 정사각형을 취했습니다. 각각의 정사각형에서는 224x224의 크기를 각 귀퉁이와 중간에서 crop한 5가지와 이미지를 224x224로 resize 했습니다. 그리고 Flip까지 시켜 하나의 이미지에서 총 4x3x6x2=144개의 샘플을 얻을 수 있었습니다.
- Softmax prediction은 각각의 crop들을 평균내고 또한 classifier들을 취합해 구했습니다.
그 결과는 다음과 같습니다.
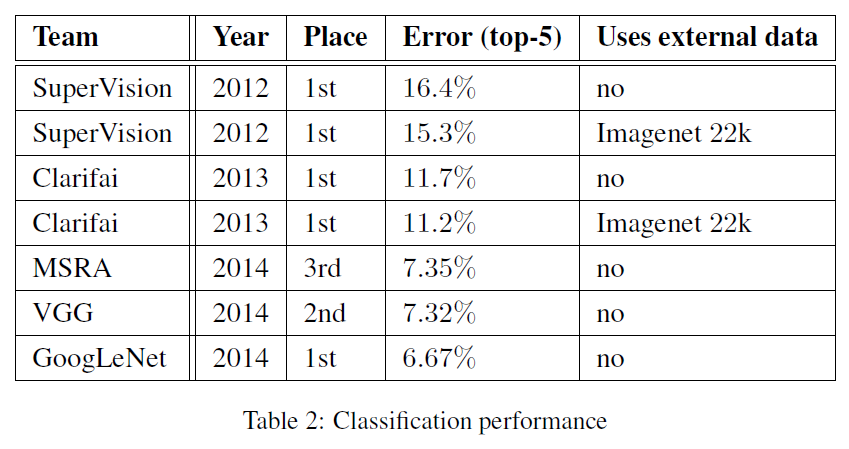
별도의 데이터를 사용하지 않았음에도 불구하고 top-5 error 6.67% 1위를 차지했습니다. 또한 본 논문에서는 multiple testing choice에 대한 실험도 진행했습니다.
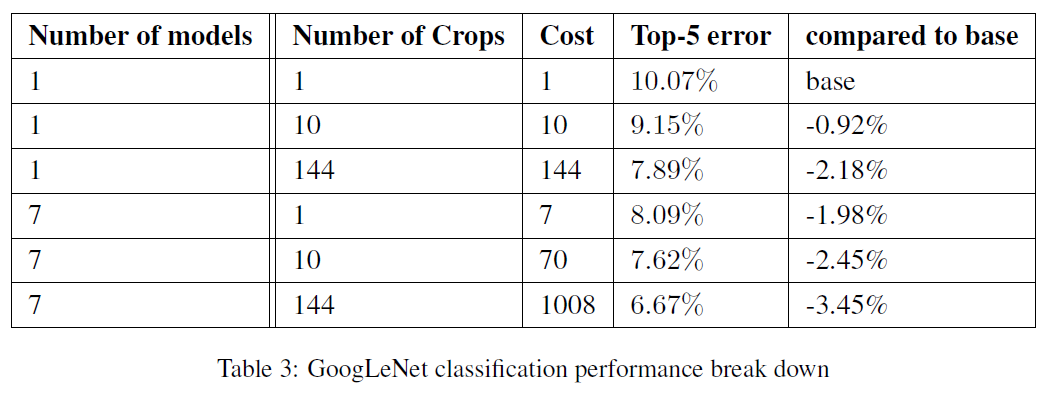
Ensemble을 적용하고 crop을 최대한 많이 적용할 수록 좋은 성과가 나타났습니다.
8. ILSVRC 2014 Detection Challenge Setup and Results
ILSVRC detection task는 200개의 class에 해당하는 이미지에서 bounding box를 그려야 합니다. Bonding box가 최소 50%는 겹치고 해당 class가 맞게 분류되었으면 정답으로 계산합니다. False positive(실제론 아니지만 맞다고 하는것)인 경우에는 페널티를 부과합니다. Classification task와는 다르게 각각의 이미지는 하나이상의 물체들을 갖고있으며 scale 또한 매우 다릅니다. 평가는 mAP(mean avearge precision)으로 계산합니다.
GoogLeNet의 접근 방식은 R-CNN과 유사하지만 region classifier를 Inception으로 사용했습니다. 게다가 region proposal을 더 나은 object recall을 위해 multi-box prediction과 Selective Search를 섞어서 적용했습니다. False positive를 줄이기 위해 superpixel을 두배로 늘렸는데 이는 Selective Search부터의 proposal을 반으로 줄입니다. 그 결과 1%의 mAP 상승이 이뤄졌고, 6개의 CNN을 ensemble하여 각각의 region을 classify했습니다. 그 결과 40%에서 43.9%로 향상되었습니다.
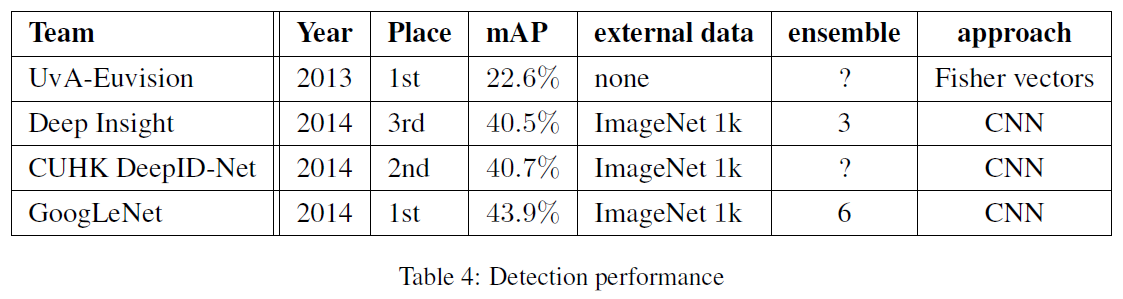
그 결과는 위 표와 같습니다. External data로 ILSVRC 2012 classification의 데이터를 사용했습니다. 그 결과 전년도(2013)에 비해 거의 2배정도 성능이 향상되었습니다. Single model간의 비교는 아래와 같습니다.
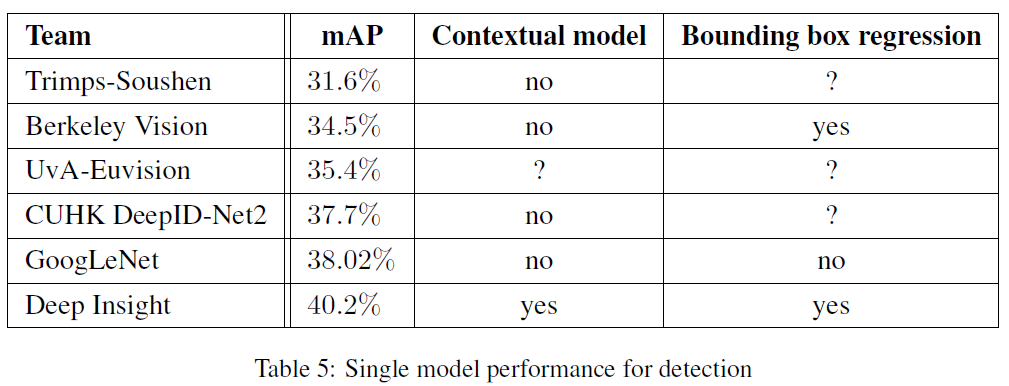
Deep Insight는 단일 모델로는 40.2%의 mAP를 보였는데, ensemble 모델을 사용했을 경우 40.5%로 고작 0.3%의 상승밖에 보이지 않았지만, GoogLeNet은 38.02%에서 43.9%로 5.88%의 큰 상승폭을 이뤘습니다.
References
[1] https://arxiv.org/abs/1409.4842




댓글