이번 포스팅에서는 Tero Karras et al.이 ICLR 2018에서 발표한 "Progressive Growing of GANs for Improved Quality, Stability, and Variation"을 읽고 리뷰해보도록 하겠습니다.
PGGAN은 현재 GAN 분야에서 sota를 달성하고 있는 StyleGAN 시리즈의 기반이 되었습니다.
1. Introduction
GAN을 이용하여 고해상도의 이미지를 생성하는 것은 아주 어려운 태스크입니다. 고해상도의 이미지를 생성하도록 generator를 학습시키는 경우 학습 이미지의 distribution과 학습 결과 생성된 이미지의 distribution의 차이가 커집니다. 또한 고해상도의 이미지는 같은 자원에서 저해상도의 이미지보다 적은 배치사이즈를 가져가게 하는데, 이는 불안정한 학습을 야기합니다. 이러한 상황에서 본 논문에서는 generator와 discriminator를 저해상도의 이미지로부터 고해상도의 이미지로까지 layer들을 추가하면서 점진적으로 커지게합니다. 이를 통해 학습 속도를 향상시키고 고해상도에서도 안정적인 학습을 가능케 했습니다.
논문이 발표된 당시, 생성된 이미지의 quality 뿐만 아니라 variation (diversity)까지도 함께 고려하고 측정하고자하는 많은 시도가 있었습니다. 본 논문에서도 또한 3장에서 variation을 향상시키기 위한 방법들을 제시하고, 5장에서 quality와 variation을 측정하기 위한 새로운 metric을 제시합니다.
4.1절에서는 네트워크를 초기화할때의 약간의 변화에대해 서술하고, 다른 layer들 사이에서 균형잡힌 학습 속도를 확보합니다. 게다가, mode collapse는 discriminator가 overshoot하기에 발생하는데, 이를 해결하기 위한 방법을 4.2절에서 제시합니다.
기존 연구들에서 사용되었던 데이터셋 (CelebA, LSUN, CIFAR10)은 모두 저해상도의 이미지에 해당합니다. 그래서 본 논문에서는 1024x1024로 고해상도의 데이터셋 CelebA-HQ를 만들어서 공개했습니다.
2. Progressive Growing of GANs
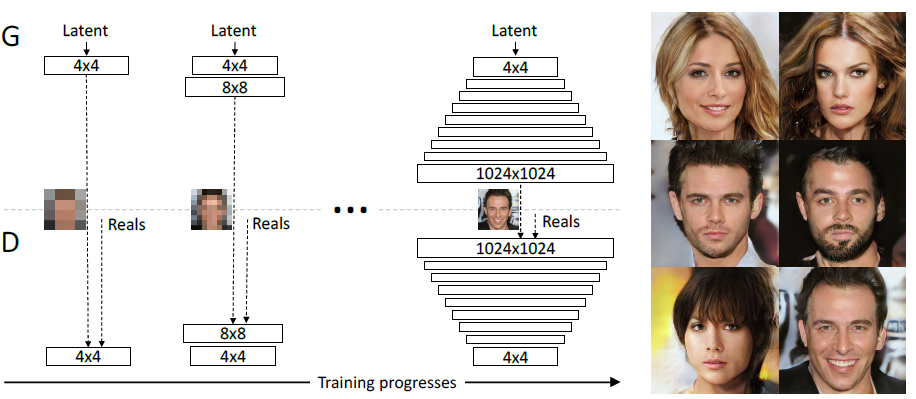
본 논문의 주요한 contribution은 GAN을 학습시킬때 저해상도의 이미지부터 시작하여 위의 사진처럼 layer를 추가해가면서 고해상도에 도달하게 하는 것입니다. 이를 통해 image distribution에서 큰 구조의 (coarse-grained) 특징들을 우선 학습하고, 점차 세밀한 (fine-grained) 특징들을 이어서 학습하는 것입니다.
Generator와 discriminator는 서로 반대되는 구조를 갖고 있습니다. 모든 layer들은 학습하는 동안 고정되어 있고, layer가 추가되면 아래 그림처럼 부드럽게 흐려지게 합니다. 이를 통해 새로운 layer가 추가되었을 때 기존 layer에 대한 충격을 완화할 수 있습니다.

본 논문에서는 이러한 progressive training이 몇가지 장점을 갖고있다고 합니다. 초기 학습에서 저해상도의 이미지를 학습하는것은 훨씬 안정적입니다. 해상도를 조금씩 늘려가면서 학습하는 것은 1024x1024의 바로 학습하는 것보다 훨씬 쉬운 문제로 변환됩니다. 그리고 마지막으로 학습 시간이 단축됩니다. 한번에 고해상도의 이미지를 학습하는 것 보다 최종 해상도에 따라 최대 6배정도 학습 속도가 향상되었다고 합니다.
3. Increasing Variation using Minibatch Standard Deviation
GAN은 학습 이미지에서의 variation만 포착하는 경향이 있습니다. 이에 Salimans et al.은 minibatch discrimination을 제안했는데, 각각의 이미지에서 뿐만 아니라 minibatch에서도 feature statistics를 계산하여 실제 이미지와 생성된 이미지를 비슷한 statistic을 가지도록 했습니다. 본 논문에서는 이를 새로운 파라미터나 하이퍼파라미터의 도입 없이 더욱 간소화시켰습니다. 우선, minibatch에 대해 각각의 spatial location의 feature의 std.를 계산합니다. 그 다음에 이를 모든 feature와 spatial location에 대해 평균을 내어 하나의 single value로 만들고, 이를 minibatch의 모든 spatial location에 대해 복제하고 concatenate하여 하나의 constant feature map을 만듭니다. 이 map은 discriminator에 어디에 넣어도 좋지만, 가장 마지막에 넣는 것이 좋다고 합니다.
4. Normalization in Generator and Discriminator
GAN은 generator와 discriminator의 비정상적인 경쟁에 의해 발생하는 gradient에 취약합니다. 이를 다시 얘기하자면 두 network의 학습 속도가 다르다는 뜻으로 해석 될 수 있습니다. 기존 연구에서는 batch normalization을 추가하는 등의 조치를 취했지만, 본 논문에서는 이러한 signal을 직접적으로 규제하는 방법을 제시합니다.
4.1. Equalized Learning Rate
본 논문에서는 단순한 standard normal distribution으로 weight을 initialize합니다. 그 다음에 실행중에 weight를 scaling 하는데, \(\hat{w}_i=w_i/c\)이고, \(c\)는 He initialization에서 사용된 per-layer normalization costant입니다. \[\frac{1}{c}=\sqrt{\frac{2}{n_{in}}}\]
이를 통해 weight의 update가 파라미터의 scale에 영향받지 않고 진행됩니다. 따라서, dynamic range와 학습 속도가 모든 weight에 똑같이 적용됩니다.
4.2. Pixelwise Feature Vector Normalization in Generator
Generator와 discriminator의 gradient가 통제를 벗어나는 (spiral out of control) 경우를 방지하기 위해서, 본 논문에서는 feature vector의 단위 길이 만큼 각 pixel을 normalize합니다. 본 논문에서는 이를 AlexNet에서 소개되었는 local response normalization의 변형으로 구현했습니다.
\[b_{x,y}=a_{x,y}/\sqrt{\frac{1}{N}\sum^{N-1}_{j=0}{a^j_{x,y}}^2+\epsilon}\]
5. Multi-scale Statistical Similarity for Assessing GAN Results
GAN을 평가할때 사용되던 MS-SSIM은 큰 규모의 mode collapse는 잘 포착하지만 variation (diversity)의 손실이라던가 하는 작은 변화는 잘 포착하지 못한다고 합니다. 따라서 본 논문에서는 Laplcian pyramid를 활용합니다. 16,384(2^14)개의 이미지를 샘플링하고 pyramid의 각 level에서 128(2^7)개의 descriptor를 추출하여 layer마다 총 2^21개의 descriptor가 생깁니다. 각 descriptor는 7x7에 RGB 3 채널로 이루어져 있어 총 dimension이 147입니다. Pyramid의 \(l\)번째 feature에서 실제 이미지와 생성된 이미지에서의 패치를 각각 \(\{x^l_i\}^{2^{21}}_{i=1}, \{y^l_i\}^{2^{21}}_{i=1}\)이라고 할 때, 둘을 각각의 채널별로 normalize하고 그 둘의 sliced Wassertein distace (SWD)를 구합니다. SWD가 적게 나오면 두 패치의 distribution이 비슷하다는 것이고, 해당 resolution에서 appearance와 variation 두 측면에서 모두 비슷하다고 볼 수 있습니다.
6. Experiments
6.1. Importance of Individual Contributions in terms of Statistical Similarity
본 논문에서는 SWD와 MS-SSIM을 각각의 contribution의 성능을 측정하기 위해 사용했습니다. Baseline은 WGAN-GP를 적용한 Gularajani et al.의 training configuration입니다.
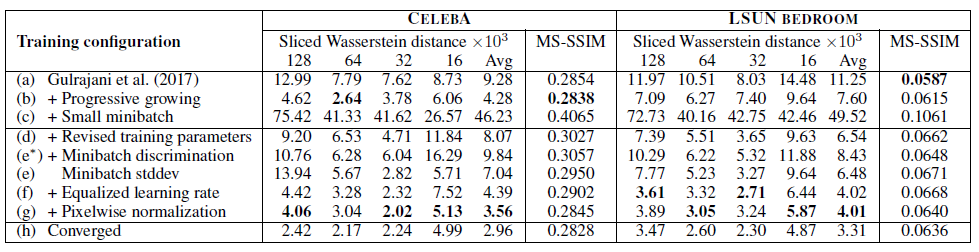

(a)에서가 (h)보다 더 좋지 않은 이미지를 생성하고 있지만, MS-SSIM으로 측정한 결과 둘의 차이가 크지 않았습니다. 이에 반해 SWD는 큰 차이를 보이고 있습니다. 따라서, SWD가 MS-SSIM과는 달리 color, texture, viewpoints 등의 variation을 잘 포착하고 있음을 알수 있습니다.
고해상도의 이미지를 다루기 위해서는 배치 사이즈를 줄여야 하므로 (c)에서는 배치를 64에서 16으로 줄였습니다. 그러나 생성 결과가 매우 불안정해졌고 (d)에서 BatchNorm이나 LinearNorm을 제거하는 등, training parameter를 수정하고 나니 학습이 안정적으로 진행되었습니다. (e*)에서는 Salimans et al.의 minibatch discrimination을 적용시켰는데 성능향상을 보이진 못했고, (e)에서는 본 논문의 minibatch standard deviation을 적용시켰더니 SWD에서 성능 향상을 볼 수 있었습니다. 나머지 (f),(g)에서도 성능 향상이 나타났습니다. 마지막으로 (h)에서는 학습을 충분히 시켜 수렴시킨 결과입니다.
6.2. Convergence and Training Speed
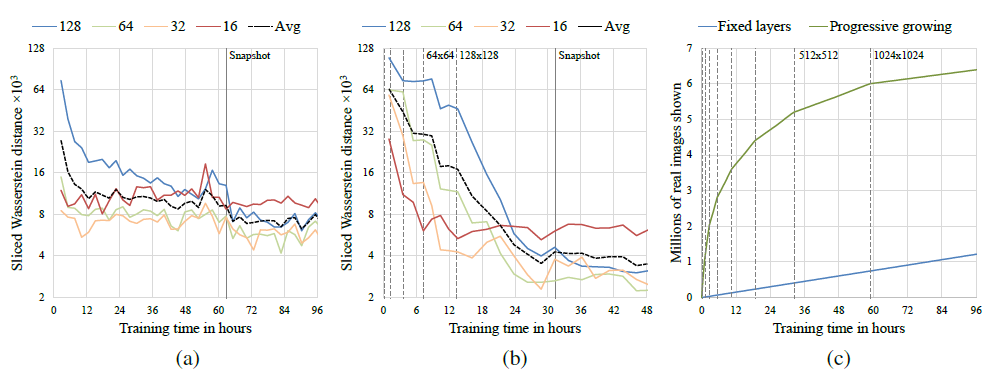
(a)와 (b)의 비교를 통해 progressive growing을 통해 더 나은 최적값에서 모델이 수렴되고, 2배정도 학습 시간이 단축되는 것을 확인 할 수 있었습니다. (c)에서는 해상도가 증가함에 따라, progressive growing의 방식이 더 빨라짐을 보여주고 있습니다.



댓글